



|
|
|
|
Auf der Definition der Relevanz bauen die beiden am häufigsten verwendeten Evaluierungsmaße auf:
 3.5.3.1: Precision und Recall
3.5.3.1: Precision und RecallPrecision gibt also den Anteil der relevanten Dokumente unter den gefundenen Dokumenten an, Recall gibt den Anteil der relevanten Dokumente an, die gefunden wurden. Optimal, nämlich gleich 1 , sind die Werte für Precision und Recall natürlich genau dann, wenn Dq=r-1q({1}) gilt, wenn also genau alle relevanten Dokumente als Antwortmenge zurückgeliefert werden.
Die beiden Maße sind in gewisser Weise gegenläufig. Zur Illustration kann man die beiden Extremfälle betrachten: Wenn Dq=D gilt, wenn also alle Dokumente auf die Anfrage hin zurückgeliefert werden, ist der Recall gleich 1 :
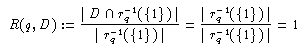
Wird umgekehrt nur ein einziges relevantes Dokument
dr D gefunden, so ist
D gefunden, so ist
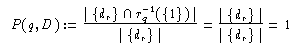
In der Regel werden die Antwortmengen aber zwischen diesen beiden Extremen liegen. Dann ergibt sich im Allgemeinen bei einer Verkleinerung der Antwortmenge durch eine spezifischere Anfrage eine bessere Precision aber ein schlechterer Recall, bei einer Vergrößerung der Antwortmenge durch eine allgemeinere Anfrage ein größerer Recall aber eine kleinere Precision. Ähnliche Situationen können auftreten, wenn Precision- und Recallmaße dazu verwendet werden, verschiedene Systeme zu vergleichen. Eindeutige Aussagen darüber, ob ein System besser ist als das andere, können nur gemacht werden, wenn für das eine System sowohl der Precisionwert als auch der Recallwert besser ist als bei dem anderen System. Ist bei einem System z. B. die Precision besser, dafür aber der Recall schlechter, so eignen sich die Systeme zwar eventuell für unterschiedliche Aufgaben, es kann aber nicht allgemein gesagt werden, welches besser ist.
Die Gegenläufigkeit der Maße wird besonders interessant, wenn die Größe der Antwortmenge des Systems durch einen Parameter steuerbar ist, wie dies bei den Vektorraummodellen (siehe Abschnitt _3.4_ ) der Fall ist. Dort wurden die Antwortmengen durch eine Ähnlichkeitsschranke bestimmt, bzw. es wurden als Antwortmengen Rangfolgen von Dokumenten geliefert. Mit einer solchen Rangfolge kann man nun den Zusammenhang zwischen Precision und Recall darstellen und gegebenenfalls die Schwelle so festlegen, dass die gewünschte Art der Antwortmenge erzielt wird.
3.5.3.2: Abbildung 34 gibt ein Beispiel und die zugehörige graphische Darstellung an.
Abb. 34: Beispiel eines Precision Recall DiagrammsFalls die Antwortmenge nicht vollständig geordnet ist, also z. B. beim Vektorraummodell mehrere Dokumente die gleiche Ähnlichkeit zur Anfrage haben, muss darauf geachtet werden, dass die Werte in der Folge nicht durch willkürliche Vergabe der Rangplätze beeinflusst werden. Wäre im Beipiel der Abbildung _34_ jeder Block eine Gruppe von Dokumenten mit gleicher Ähnlichkeit zur Anfrage, so könnten die Dokumente innerhalb der Blöcke zufällig angeordnet werden. Das würde das Precision Recall Diagramm beeinflussen. So könnte das 14. Element der Folge auch ((14)/(17),(14)/(31)) oder ((14)/(17),(14)/(40)) lauten.
Eine Möglichkeit, das Problem zu lösen, ist Precision - Recall Paare nur für die verschiedenen Ähnlichkeitswerte zu berechnen, also für jede Ähnlichkeitsschranke eine eigenständige Auswertung zu machen. Im Beispiel der Abbildung _34_ würde sich (für den konstruierten Fall, dass jeder Block eine Ähnlichkeitsstufe darstellt) eine Folge aus 19 Gliedern ergeben, die folgendermaßen anfängt: ((6)/(30),(6)/(10)),((11)/(30),(11)/(20)),((13)/(30),(13)/(30)),((14)/(30),(14)/(40)),((17)/(30),(17)/(50)), Vergleicht man die Precision an gleichen Recallwerten, zeigt sich, dass die erste Art der Berechnung bessere Precisionwerte liefert. Das liegt daran, dass der Precisionwert in diesem Fall nur für die Dokumente berechnet wird, die in der Ordnung vor dem jeweiligen relevanten Dokument liegen, während bei der Blockberechnung eventuell auch nichtrelevante Dokumente einbezogen werden, die zwischen dem relevanten Dokument und der Blockgrenze liegen.
Weitere Verfahren zur Berechnung von Precision Recall Diagrammen im Fall von nicht vollständig geordneten Antwortmengen finden sich in Fuhr (1995 [->]).
|
|
|
|