



|
|
|
|
In den Beispielen, die wir bisher betrachtet haben, waren die Attribute maximal dreiwertig (Abbildung _6_ ). Dabei wurden die Wertebereiche Ri stets nur als Mengen betrachtet. Weitere Strukturen wie z. B. Ähnlichkeiten zwischen Werten wurden nicht berücksichtigt. Nun wird aber beim ID3 Algorithmus für jeden Wert, den ein Attribut in der Beispielmenge annimmt, ein neuer Kindknoten angelegt. Das kann zum einen dazu führen, dass es bei großen Wertebereichen sehr viele Knoten gibt und damit der Baum sehr groß wird, zum anderen kann es bedeuten, dass z. B. bei reellen Meßwerten Werte, die sich nur minimal unterscheiden, also z. B. durch zufällige Schwankungen an einem Meßgerät zustande gekommen sind, genauso als verschieden angesehen werden, wie Werte mit sehr großer Differenz.
Um diese Fragen genauer zu beschreiben, kann man verschiedene Grade der inneren Ordnung von Mengen, sog. Skalenniveaus, definieren.
 4.2.7.1: 4.2.7.2: 4.2.7.3: 4.2.7.4:
4.2.7.1: 4.2.7.2: 4.2.7.3: 4.2.7.4: Der ID3 Algorithmus nutzt nur Nominalskaleneigenschaften: Es wird für jeden angenommenen Wert eines Attributs ein neuer Kindknoten angelegt. Im Auswahlkriterium werden nur Häufigkeiten verwendet. Möglicherweise vorhandene weitere Strukturen der Wertebereiche, wie etwa Ähnlichkeiten von, oder Abstände zwischen Attributwerten bleibt ungenutzt. Dieses Wissen kann allerdings in die Definition der Attribute gesteckt werden, wie es in dem Beispiel von Carter and Catlett (1987 [->]) (siehe Abbildung _6_ ) getan wurde. Dort war als Attribut eine binäre Schwellwertfunktion der Form
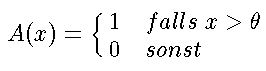
|
|
|
|