



|
|
|
|
Wird der ID3 Algorithmus auf ein inkonsistentes Trainingsset
angewendet, bricht das Verfahren zusammen. In diesem Fall existieren
zwei Tupel s=(s0,...,sn), t=(t0,...,tn) T , die auf den vorhersagenden Attributen
A0,...,Am-1 die selben Werte haben, auf den vorherzusagenden
Attributen Am,...,An aber verschiedene Werte, für die also gilt:
T , die auf den vorhersagenden Attributen
A0,...,Am-1 die selben Werte haben, auf den vorherzusagenden
Attributen Am,...,An aber verschiedene Werte, für die also gilt:
 i{m,...,n},
i{m,...,n},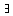 j{0,...,m-1} s.d. sj
j{0,...,m-1} s.d. sj tj
tj
Datensammlungen können aus vielen Gründen inkonsistent sein:
Entsprechend der verschiedenen Ursachen kann mit Inkonsistenzen in Trainingsdaten unterschiedlich umgegangen werden (wenn die Ursachen denn erschlossen werden können).
Handelt es sich um kleine Anzahlen unsystematischer Eingabefehler, können die fehlerhaften Tupel aus dem Trainingsset entfernt werden. Bei größeren Fehlerzahlen kann es schwierig werden, zu entscheiden, welche Einträge korrekt sind und welche fehlerhaft. Bei systematischen Eingabefehlern kann die Repräsentativität des Trainingssets leiden.
Bei unterschiedlicher manueller Kategorisierung kann versucht werden, die Gründe der Unterschiede, also z. B. den Zeitpunkt der Kategoriesierung oder die Person, die die Kategorisierung durchgeführt hat, als zusätzliches Attribut zu verwenden, um so eine konsistente Kategorisirung zu erreichen. Eine andere Möglichkeit besteht darin, Kategorien, die zu Inkonsistenzen führen, zusammenzulegen, sodaß das Trainingsset bezüglich der neuen Kategorisierung konsistent ist. Theoretisch ist das immer möglich, da man im schlimmsten Fall (der damit auch der am wenigsten nützliche ist) nur noch eine einzige Kategorie übrig behält, bezüglich der aber jedes Trainingsset natürlich konsistent ist. Es bleibt also im Einzelfall zu prüfen, ob eine solche vergröberte Kategorisierung noch nützlich ist.
Ähnlich kann man auch im letzten Fall verfahren: Datensammlungen, die in einer feinen Kategorisierung inkonsistent sind, da eigentlich nur Wahrscheinlichkeitswerte über die Zugehörigkeit zu einer bestimmten Kategorie vorliegen, können für eine wesentlich gröbere Kategorisierung konsistent sein. In vielen Fällen ist es aber unzweckmäßig, das Trainingsset in eine deterministische Form zu zwingen, weil sie dem Bereich, aus dem die Beispiele stammen, nicht angemessen ist. In diesen Fällen kann eine statistische Aussage, die z. B. Wahrscheinlichkeiten für die Zugehörigkeit von Beispielen zu verschiedenen Kategorien angibt, viel nützlicher sein.
Die meisten KDD Verfahren, die Kategorisierungsalgorithmen konstruieren, setzen konsistente Trainingssets vorraus. D. h. Trainingssets müssen vor der Verwendung im KDD Verfahren auf Konsistenz geprüft werden und gegebenenfalls durch eine geeignete Vorbehandlung ( preprocessing) in eine konsistente Form gebracht werden. Bei diesem Vorgehen geht aber im Allgemeinen die Information über die Inkonsistenzen, die ja in vielen Fällen durchaus wichtig sein kann, verloren. Besser wäre es, Inkosistenzen im eigentlichen KDD Algorithmus zu bearbeiten und soweit wie möglich auch zur Beschreibung der Daten zu nutzen.
|
|
|
|