



|
|
|
|
Neben dem Ableiten vereinfachter Attribute können neue
Attribute auch aus mehreren Attributen zusammengesetzt werden. Auch
dabei muss natürlich darauf geachtet werden, dass das Skalenniveau
der Attribute diese Operationen erlaubt. Unter einem zusammengesetzten
Attribut versteht man also eine Funktion, in die mehrere Attribute
eingehen. Als Beispiel kann man zu zwei reellwertigen Attributen
A1,A2:D->
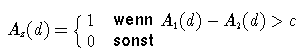
Die Menge möglicher Funktionen, nach denen zusammengesetzte Attribute konstruiert werden können, ist im Allgemeinen sehr groß. Sie kann deshalb nicht vollständig nach geeigneten Funktionen durchsucht werden. Man muss sich also auf eine handhabbare Klasse von Funktionen beschränken. Eine solche Klasse ist z. B. die der Linearkombinationen aus Attributen, die mit einer Schwellwertfunktion versehen sind. Sie setzt natürlich Attribute mit einem entsprechenden Skalenniveau, also z. B. Intervallskalen, voraus. (Manchmal kann es sinnvoll sein, Attribute mit Nominalskalen in einzelne Attribute zu zerlegen, die angeben, ob ein Wert angenommen wird oder nicht. Diese binären Attribute können dann mit {0,1} kodiert und in eine Linearkombination einbezogen werden (siehe Brodley und Utgoff, 1995 [->]), auch wenn sie streng genommen kein Intervallskalenniveau haben.)
Brodley und Utgoff (1995 [->]) vergleichen verschiedene Verfahren, mit denen multivariate Entscheidungsbäume mit Linearkombinationen von reellwertigen Attributen berechnet werden können. Dabei unterscheiden sie zunächst zwischen der Entscheidung zwischen nur zwei Zielmengen und der Einteilung in n>2 Zielmengen. (Hier wird von Zielmengen gesprochen, weil es sich um die Entscheidungen in einem Knoten handelt. Deshalb brauchen die Zielmengen keine Kategorien zu sein.) Bei zwei Zielmengen - also bei einem binären Entscheidungsbaum - kann man mit linearen Schwellwertfunktionen ( linear threshold unit LTU) arbeiten. Dazu benötigt man einen Vektor x=(x0,...,xn) aus Koeffizienten für die beteiligten Attribute und einer Schwelle x0 . Übersteigt die mit den Koeffizienten gewichtete Summe der Attributwerte w1,...,wn die gegebene Schwelle, wird die eine Zielmenge angenommen, liegt sie unter der Schwelle, die andere. Die lineare Schwellwertfunktion ist also durch einen Koeffizientenvektor charakterisiert, der einen Koeffizienten mehr enthält (die Schwelle) als Attribute bearbeitet werden. Die Bedingung läßt sich mit w0=-1 , d:=(w0,w1,...,wn) als Skalarprodukt d*x>0 schreiben.
Bei mehr als zwei Zielmengen wird für jede Zielmenge ein solcher Koeffizientenvektor benötigt. Ein Tupel wird derjenigen Zielmenge zugewiesen, für die die mit dem zugehörigen Koeffizientenvektor gewichtete Summe der Attributwerte am größten ist (dieses Verfahren wird auch als lineare Maschine ( linear machine) LM bezeichnet).
Formal gesehen ist die lineare Schwellwertfunktion ein Spezialfall der linearen Maschine: Hat man eine lineare Maschine mit zwei Zielmengen, kann man die Entscheidung so charakterisieren:
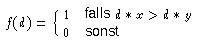
Brodley und Utgoff unterteilen die Konstruktion einer multivariaten Entscheidungsfunktion für einen Knoten in verschiedene Schritte:
 4.4.1.1: Attributauswahl4.4.1.2: Koeffizientenbestimmung4.4.1.3: Evaluierung
4.4.1.1: Attributauswahl4.4.1.2: Koeffizientenbestimmung4.4.1.3: EvaluierungInsgesamt muss aber gesagt werden, dass bei den multivariaten Verfahen so viele Variationsmöglichkeiten bestehen, dass die beschriebene Untersuchung allenfalls Hinweise auf Unterschiede und Einflussfaktoren geben kann, sicherlich aber keine abschließende Berwertung der Verfahren darstellt.
|
|
|
|