



|
|
|
|
Die Produktformel für die Wahrscheinlichkeit unabhängiger Ereignisse und die Bayes'sche Formel werden im folgenden verwendet, um mit vereinfachenden Annahmen die gesuchte Wahrscheinlichkeit für die Beurteilung der Relevanz eines Dokuments herzuleiten. Sie kann jetzt als bedingte Wahrscheinlichkeit geschrieben werden. Dazu verwendet Fuhr (1995 [->]) das Ereignis R "Ein Dokument wird als relevant eingeschätzt" und schreibt P(R | q,d) , also die bedingte Wahrscheinlichkeit dafür, dass eine Relevanz angegeben wird, unter der Bedingung, dass die Anfrage q und das Dokument d vorliegen.
Der zugrundeliegende Grundraum ist das kartesische Produkt
G=D×Q×{R,NR} , wobei Q die Menge aller Anfragen und R bzw. NR die Beurteilung als relevant bzw. nicht relevant
bedeuten. Die Schreibweise der Bedingung mit einem Komma entspricht dem
Durchschnitt der Mengen, die durch geeignet definierte Attribute mit
diesen Werten beschrieben werden können. Sei Ar:G->{R,NR} das Attribut, das angibt, ob ein Element aus dem
Grundraum als relevant beurteilt wurde oder nicht, und Aq:G->Q das Attribut, das die verwendete Anfrage beschreibt,
dann ist die Bedingung R,q=((Ar=R) (Aq=q)) , also die Menge der Elementarereignisse, bei denen
ein Dokument für die Anfrage q als relevant beurteilt wurde.
(Aq=q)) , also die Menge der Elementarereignisse, bei denen
ein Dokument für die Anfrage q als relevant beurteilt wurde.
Um die bedingte Wahrscheinlichkeit P(R | q,d) abschätzen zu können, geht man
zunächst zu einfacheren Repräsentationen von Dokument und
Anfrage über. Dazu sei T={t1,...,tN} die Menge der Terme, die in einer Dokumentsammlung
D vorkommen. Eine Anfrage q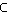 T wird als die Menge von Termen dargestellt und ein
Dokument d ebenfalls als dT oder als Vektor von Attributen bzw. Zufallsvariablen
A1,...,AN mit
T wird als die Menge von Termen dargestellt und ein
Dokument d ebenfalls als dT oder als Vektor von Attributen bzw. Zufallsvariablen
A1,...,AN mit
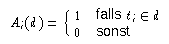
 {0,1}N bezeichnet.
{0,1}N bezeichnet.
Eine weitere Darstellungsmöglichkeit für die Chance, dass ein Ereignis auftritt, ist der Quotient der Wahrscheinlichkeit mit der Wahrscheinlichkeit des Komplementärereignisses, die Quote des Ereignisses ( Odds).
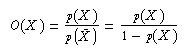
Die Quote ist <1 für Wahrscheinlichkeiten <0.5 und >1 für Wahrscheinlichkeiten >0.5 . Sie ist streng monoton, liefert also dieselbe Rangfolge für Ereignisse wie die Wahrscheinlichkeit. Sie erlaubt aber manchmal einfacheres Rechnen.
Statt der gesuchten bedingten Wahrscheinlichkeit des gesuchten Ereignisses "Es wird ein positives Relevanzurteil unter der Bedingung des Dokuments d und der Anfrage q abgegeben", wird nun ihre Quote
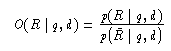
Zunächst folgt mit p(d | Rq)=(p(dRq))/(p(Rq)) und damit p(Rq)·p(d | Rq)=p(Rdq)
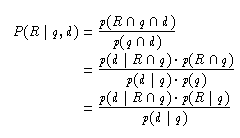
Es folgt also
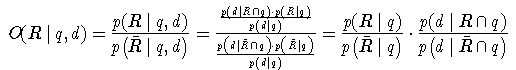
Um diese Wahrscheinlichkeit zu schätzen, müssten zu allen Anfragen Dokumente mit Relevanzbeurteilungen vorliegen. Da dieser Aufwand selten zu leisten ist, wird die Berechnung im nächsten Schritt auf die Terme heruntergebrochen. Dazu wird die starke (und unrealistische) Annahme gemacht, dass das Auftreten von Termen in Dokumenten unabhängig ist. So ergibt sich (mit I={1,...,N} )
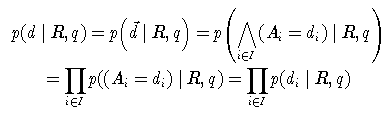
Für die Quote gilt dann:
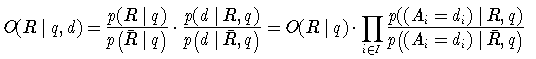
Man kann die Unabhängigkeitsannahme etwas abschwächen, indem man direkt annimmt, dass
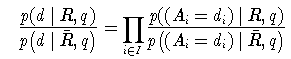
Zur weiteren Vereinfachung wird angenommen, dass für alle
tiT\q gilt, dass p(Ai=di | R,q)=p(Ai=di |
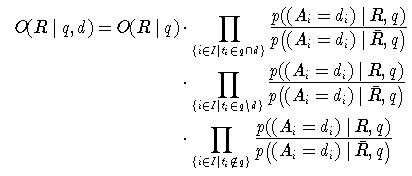
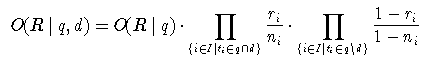
Meistens geht es darum, verschiedene Dokumente in eine Rangfolge bezüglich einer Anfrage zu bringen. Es interessieren also vor allem solche Faktoren des Produktes, die sich bei verschiedenen Dokumenten ändern. Um diese zu isolieren, kann man folgende Umformung vornehmen, bei der ein Faktor 1 aufmultipliziert und geeignet aufgespaltet wird:
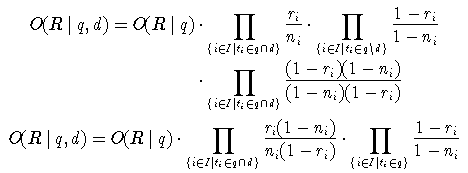

Um die Werte zu schätzen, kann eine Menge von Dokumenten verwendet werden, für die bekannt ist, ob sie für eine Anfrage relevant sind oder nicht. Diese Information kann z. B. durch Relevance Feedback Methoden ermittelt werden, also durch die Einschätzung der Relevanz der gefundenen Dokumente durch die Nutzenden. Als Schätzung für ri kann man die Anzahl reli der relevanten Dokumente, die den Term ti enthalten, durch die Gesamtzahl rel der relevanten Dokumente teilen:
Bei dieser Schätzung ergeben sich besonders bei kleinen Dokumentmengen Probleme, wenn eine der relativen Häufigkeiten Eins oder Null ist. In diesen Fällen ist entwerder der Bruch oder der Logarithmus nicht definiert. Ist das nicht der Fall, ergibt sich für den Retrievalstatus der Schätzwert:
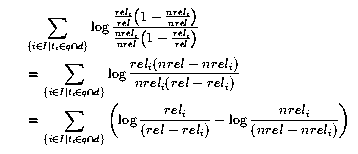
 Abb. 69: Beispiele mit Relevanzangaben zur Schätzung des Retrievalstatuswertes zu einer Anfrage Abb. 70: Neue Dokumente und ihr Retrievalstatuswert
Abb. 69: Beispiele mit Relevanzangaben zur Schätzung des Retrievalstatuswertes zu einer Anfrage Abb. 70: Neue Dokumente und ihr RetrievalstatuswertBei diesem Verfahren muß zu jeder Anfrage zunächst eine Menge von Dokumenten auf ihre Relevanz bezüglich der Anfrage beurteilt werden, damit anschließend zusätzliche Dokumente bewertet werden können. Das ist immer noch ein aufwändiges Verfahren.
Eine Möglichkeit dieses Verfahren zu verallgemeinern besteht darin, über verschiedene Anfragen zu mitteln, d. h. solche Terme hoch zu gewichten, die in vielen Dokumenten viel zu der Summe des Statuswertes beitragen.
|
|
|
|