



|
|
|
|
Ähnlich wie im vorigen Abschnitt entwickelt, wird bei der Robertson-Sparck Jones Formel (Robertson, Walker, Hancock-Beaulieu & Gatford TREC 3 [->]; Robertson, Walker, Beaulieu, Gatford & Payne TREC 4 [->]) vorgegangen, mit der Gewichte für Terme in Abhängigkiet von einer Anfrage berechnet werden können. Als Gewicht für einen Term tk wird der Wert
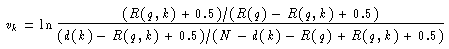
In diese Formel gehen also wie beim probabilistischen Retrieval Modell aus dem vorhergehenden Abschnitt sowohl Relevanzbeurteilungen, die entweder aus Trainingsdaten oder aus dem Relevance Feedback stammen können, als auch statistische Daten des entsprechenden Terms (wie die Dokumenthäufigkeit) ein.
Betrachtet man die Definition des Retrievalstatuswert des probabilistischen Modells und der Robertson Spark-Jones Formel genauer, ergibt sich im Einzelnen: R(q,k)=relk , R(q)=rel , N-R(q)=nrel , d(k)-R(q,k)=nrelk . Bis auf die Addition von 0.5 stimmen also die Robertson Spark-Jones Formel und ein Summand im Retrievalstatuswert des probabilistischen Modells überein.
Wenn keine Relevanzdaten vorliegen, können R(q) und R(q,k) auf Null gesetzt werden. Dann wird aus der Robertson - Spark Jones Formel eine IDF Formel:
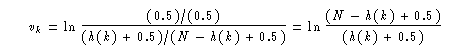
 {j | qj=1}vj=j=1nvj·qj
{j | qj=1}vj=j=1nvj·qj
 {0,1}n oder einem anderen Ähnlichkeitsmaß
verwendet werden. Im Fall des Skalarprodukts ergibt sich damit im
Wesentlichen der Retrievalstatuswert des probabilistischen
Modells.
{0,1}n oder einem anderen Ähnlichkeitsmaß
verwendet werden. Im Fall des Skalarprodukts ergibt sich damit im
Wesentlichen der Retrievalstatuswert des probabilistischen
Modells.
Wenn die Gewichte aufgrund eines größeren Trainingskorpus berechnet werden sollen, erfordert das einen höheren Speicher - bzw. Rechenaufwand, da zu jeder Anfrage der Wert R(q) und zu jedem Term-Anfrage Paar der Wert R(q,k) gespeichert bzw. aus den Trainingsdaten oder dem Feedback ermittelt werden muss. Das Vorgehen ähnelt dem bei der "Dynamisierung des Dokumentraumes" wie es im Abschnitt _3.4.6_ über das SMART System beschrieben wurde. Allerdings werden bei der Robertson - Spark Jones Formel im Allgemeinen die Gewichte nur im Bezug auf eine Anfrage, also auch nur in einer Sitzung verändert.
|
|
|
|