IMAGINE
Wissen aus großen Datensammlungen extrahieren
IMAGINE (Interaction Merger for Associations Gained by Inspection of Numerous Exemplars) ist ein System, mit dem inhaltliche Beziehungen zwischen Objekten aus großen Datensammlungen ermittelt werden können. Diese Beziehungen werden als Zahlenwerte dargestellt und Assoziationen genannt. Sie können verwendet werden, um Anfragen an ein Retrievalsystem mit zusätzlichen Termen zu erweitern (Queryexpansion), um zu Texten geeignete Indexterme vorzuschlagen (automatisches Indexieren), oder um zu Wörtern andere inhaltlich ähnliche Wörter zu finden (assoziativer Thesaurus).
Hintergrund
Um die Assoziation zwischen zwei Objekten - in der Regel Wörtern oder Namen - zu berechnen, wird ermittelt, wie oft die beiden Objekte gemeinsam in den Dokumenten einer Sammlung auftreten. Diese Häufigkeit wird mit dem Häufigkeitswert verglichen, der zu erwarten wäre, wenn das Auftreten der beiden Objekte statistisch unabhängig wäre, wenn sie also lediglich durch Zufall zusammen auftreten würden. Ist die tatsächlich gefundene Häufigkeit wesentlich größer als die bei Unabhängigkeit zu erwartende, wird ein inhaltlicher Zusammenhang zwischen den Objekten angenommen.
Im Information Retrieval ist es wichtig abzuschätzen, wie spezifisch ein Wort in einer Sammlung ist, d. h. zum einen, wie gut durch sein Auftreten Dokumente mit verschiedenen Inhalten voneinander unterschieden werden können (Precision), zum anderen aber auch, wieviele zu einer Anfrage relevante Dokumente mit diesem spezifischen Wort gefunden werden können (Recall). Ein einfaches, aber wichtiges Maß für die Spezifizität ist die Häufigkeit eines Wortes in einer Sammlung. Bei IMAGINE wird der Einfluss der Häufigkeit von Termen auf die Assoziation zwischen ihnen über zwei Parameter gesteuert, deren Wert mit einem Trainingsset für eine gegebene Anwendung optimiert werden kann.
Realisierung
IMAGINE arbeitet mit zwei für eine Anwendung vorgegebenen Vokabularien: dem Eingabevokabular und dem Ausgabevokabular. Es berechnet zu einem eingegebenen Text die Ähnlichkeiten zu den Termen des Ausgabevokabulars, indem es für jeden Term des Ausgabevokabulars die Assoziationen, die ihn mit den im Eingabetext gefundenen Termen des Eingabevokabulars verbinden, addiert. Anschließend werden die Terme des Ausgabevokabulars nach diesen Ähnlichkeitwerten sortiert ausgegeben. Es tragen also alle Terme des Eingabevokabulars, die in einem Text gefunden wurden, gemeinsam zu den Ähnlichkeitswerten bei. Dadurch können bei mehrdeutigen Wörtern Assoziationen zu Wörtern, die inhaltlich mit der intendierten Bedeutung verwandt sind, durch andere Wörter aus dem Begriffsumfeld dieser Beduetung verstärkt werden. So berücksichtigt IMAGINE die Kontextabhängigkeit der Bedeutung eines Wortes.
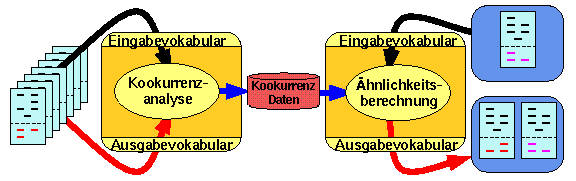
IMAGINE besteht aus zwei Komponenten, dem eigentlichen IMAGINE-Server, der Ähnlichkeitsrangreihen berechnet, und einem WWW Interface, das den Anforderungen spezifischer Anwendungen angepasst werden kann.
Anwendung und Evaluierung
In einer Studie wurde IMAGINE zur automatischen Indexierung mit einem kontrollierten Vokabular verwendet. Datengrundlage waren ca. 80 000 von Hand mit den Deskriptoren des OECD-Makrothesaurus indexierte Titel der IDIS Datenbank der British Library for Development Studies. Ziel war es, zu einem Titel die intellektuell vergebenen Deskriptoren mit IMAGINE vorherzusagen. Dazu wurden zunächst mit 500 dieser Datensätze umfangreiche Testläufe durchgeführt, in denen optimale Parameterwerte für den Einfluss der Häufigkeit von Termen ermittelt wurden. Dabei konnten gute Vorhersagewerte erzielt werden. Anschließend wurden diese Ergebnisse mit denen von 500 neuen Datensätzen verglichen. Es zeigte sich, dass die Ergebnisse, die mit den Testdaten erziehlt wurden, nicht schlechter waren als die mit den Trainingsdaten erreichten: Der Median der Rangplätze der intellektuell vergebenen Deskriptoren in den von IMAGINE für jeden Titel berechneten Rangfolgen mit ca. 3600 Deskriptoren lag für die Trainingsdaten bei 14 und für die Testdaten bei 11.
Ansprechperson:
Dr. Reginald Ferber