IMAGINE
Extracting Knowledge from Large Collections
IMAGINE (Interaction Merger for Associations Gained by Inspection of Numerous Exemplars) is a system that extracts meaningful associations between objects from large corpora of data. Such associations can be used to expand queries in an information retrieval system, to automatically index documents, or as an associative thesaurus to find related words for a specific domain.
Background
The associations between objects - usually terms or names - used by IMAGINE are based on co-occurrence data. Such data are obtained by counting how often the two objects occur together in a huge corpus of data. This observed frequency can be compared to the frequency that would be expected in case of random co-occurrence. If the observed co-occurrence is much more frequent than expected, this can be interpreted as a meaningful association between the two objects.
For retrieval systems it is important to estimate how specific a term is. Very specific terms are well suited to distinguish between documents of different content and hence yield good precision; but they tend to yield poor results in finding all documents relevant to a specific query. A simple but important measure for specificity is the overall frequency of a term. For this reason IMAGINE allows control over the impact of the overall frequencies of objects on the associations. The values of the parameters controlling this impact can be optimized for specific applications.
Implementation
IMAGINE uses two vocabularies fixed for each application: one for the input and one for the output. These vocabularies may coincide. If a text is entered to the system, IMAGINE computes a similarity value for each term of the output vocabulary. This similarity is calculated as the sum of the associations with those terms of the input vocabulary that occur in the input text. Finally the terms of the output vocabulary are sorted according to these similarity values. Thus all the terms of the input vocabulary that occur in the input text contribute to the similarity values. In this way associations of words with broad or ambiguous meanings can accumulate in output terms related to the intended meaning. In this way IMAGINE takes into account that word meaning depends on the context.
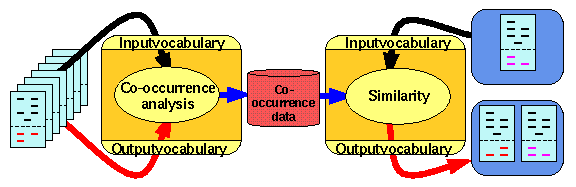
IMAGINE is implemented in two components: the IMAGINE-server that does the similarity calculations and a WWW-Interface that can be adapted to the needs of specific applications.
Application and Evaluation
IMAGINE was evaluated in a study on automated indexing of bibliographic records from the British Library for Development Studies. The collection used consisted of some 80 000 bibliographic records that had been manually indexed with the OECD Macrothesaurus. Two sets of 500 records each were separated beforehand, one to optimize the frequency impact parameters, the other to test the system with the parameters obtained. The remaining records were used to extract co-occurrence data for the words in the titles and the manually assigned thesaurus descriptors. In a large number of test runs with the first set of 500 records, good indexing results were obtained. The results for the second set that was completely new to the system were of the same quality or even better: The median rank of the manually assigned descriptors in the rank ordered lists produced by IMAGINE was 14 for the set used to optimize the parameters and 11 for the test set.
Contact:
Dr. Reginald Ferber
HTML file generated by R. Ferber: 7. 5. 1998