



|
|
|
|
Sind die Objekte der Sammlung Textdokumente, wie z. B. in einer Literaturdatenbank, so sind die wichtigsten Attribute das Auftreten von Wörtern (hier auch Terme genannt) in einem Dokument. Terme müssen dafür in geeigneter Weise definiert werden; im einfachsten Fall als zusammenhängende Zeichenketten aus Buchstaben und bestimmten Sonderzeichen, die durch Leerzeichen, Interpunktionszeichen und andere Sonderzeichen begrenzt sind. Attribute können aber auch komplexer definiert werden: Die Dokumente in Literaturdatenbanken sind z. B. in verschiedene Felder eingeteilt, die unterschiedliches Wissen enthalten (wie in Abbildung _1_ gezeigt). Hier kann ein Attribut auch das Auftreten eines Terms in einem bestimmten Feld bezeichnen.
In der Praxis ist eine Anfrage eine Verknüpfung von elementaren Anfragen, die aus einem Feldbezeichner und einem Term bestehen, durch die Operatoren AND, OR und NOT. Fehlt der Feldbezeichner wird als Voreinstellung häufig das ganze Dokument - also die Vereinigung aller Felder - angenommen. Nach der obigen Definition steht ein Term für die Menge der Dokumente, die den Term im entsprechenden Feld enthalten. Sind in einer Anfrage zwei Terme t1 und t2 mit AND verknüpft, so werden alle Dokumente angezeigt, die beide Terme enthalten. Sind sie mit einem OR verknüpft, werden die Dokumente angezeigt, die den einen oder den anderen Term (oder beide) enthalten. Lautet die Anfrage t1 AND NOT t2 werden die Dokumente ausgewählt, die zwar den Term t1 , nicht aber den Term t2 enthalten.
In verschiedenen Retrievalsystemen werden die Paare aus Feldbezeichner und Term auf verschiedene Weise abgefragt. So gibt es die Form Feldbezeichner = Term also beispielsweise
AUTHOR = Saltonoder Term
inFeldbezeichner (
Salton in AUTHOR).
Die Anfragen können mit den Operatoren durch Klammerung beliebig kompliziert geschachtelt werden. Dadurch können komplexe Anfragen formuliert werden. Es wird aber auch immer schwieriger solche Anfragen in einer einfachen Texteingabe fehlerfrei zu formulieren. Dabei können syntaktische Fehler - wie fehlende schließende Klammern - bei der Auflösung der Anfrage vom System erkannt und den Nutzenden angezeigt werden, semantische "Fehler", die also z. B. zu sich (in der Praxis) ausschließenden Bedingungen und damit zu leeren Ergebnismengen führen, können aber nur schwer abgefangen werden.
Um die Formulierung der Anfragen zu erleichtern, werden deshalb häufig elektronische Eingabeformulare verwendet, die für die verschiedenen Textfelder verschiedene Eingabefelder für Suchterme vorsehen. Das führt aber dazu, dass es in der Regel nicht mehr möglich ist, diese elementaren Anfragen in komplexere Verknüpfungen einzubeziehen, zumindest wenn verschiedene Felder beteiligt sind.
Es liegt nahe, bei der Modellierung gemäß der Definition
des Booleschen Retrievals (
_3.1.1_
) die Paare aus
Feldbezeichner und Term direkt als die Attribut-Wert-Paare zu
übernehmen. Für das Titelfeld könnte man z. B. das
Attribut xTI:D->
 D | d enthaelt t1 im Titelfeld}=
D | d enthaelt t1 im Titelfeld}=
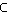 V | t1R}
V | t1R}
Das Problem lässt sich lösen, indem für jeden Term t1 ein Attribut Tt1:D->{false, true} definiert wird, das feststellt, ob der Term t1 in einem bestimmten Feld der Dokumente auftritt. Zum Paar aus dem Feldbezeichner "Titel" und dem Term t1 gehört damit die elementare Anfrage (TIt1,true) . Die zugehörige elementare Ergebnismenge
D | d enthaelt t1 im Titelfeld}
Um den Vergleichsmechanismus des Schemas aus Abbildung _11_ formal zu konstruieren, kann man die Attribute in geeigneter Weise zusammenfassen. Im ersten Fall ergäbe sich eine Dimension für jedes Feld, im zweiten Fall für jedes Feldbezeichner-Term Paar.
Da alle beteiligten Mengen endlich sind, können die Attribute als Listen gespeichert werden. Entsprechend können auch die Umkehrabbildungen als sogenannte invertierte Listen gespeichert werden. Das ist der Weg, der auch tatsächlich häufig bei der Implementierung von Booleschen Systemen benutzt wird.
|
|
|
|