



|
|
|
|
Nach dieser eher informalen Beschreibung soll nun eine formalere und ausführlichere Beschreibung gegeben werden, zunächst für die Konstruktion des Entscheidungsbaumes:
Sei
 {A0,...,An} das aktuelle Attribut, K
{A0,...,An} das aktuelle Attribut, K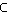 D die Menge der Beispiele, die dem Knoten zugeordnet
sind, und zR0 eine Kategorie bezeichnen.
D die Menge der Beispiele, die dem Knoten zugeordnet
sind, und zR0 eine Kategorie bezeichnen.
 diK und ein zkR0 , setze A:=A0 und z=zk .
{1,...,n} , das in K mindestens 2 verschiedene Werte annimmt (
diK und ein zkR0 , setze A:=A0 und z=zk .
{1,...,n} , das in K mindestens 2 verschiedene Werte annimmt ( 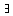 d1,d2K mit Ai(d1)
d1,d2K mit Ai(d1) Ai(d2) ), als aktuelles Attribut für den Knoten
N und füge für jeden Wert rjRi mit A-1i({rj})
Ai(d2) ), als aktuelles Attribut für den Knoten
N und füge für jeden Wert rjRi mit A-1i({rj}) KØ des Attributes einen Kindknoten Ni,rj=(A,Ki,rj) mit unbestimmtem aktuellem Attribut A und
KØ des Attributes einen Kindknoten Ni,rj=(A,Ki,rj) mit unbestimmtem aktuellem Attribut A und
K
N0,0 gehe nach Schritt 2, andernfalls beende den
Alogrithmus.In Schritt 2 muß ein Attribut Ai:D->Ri ausgewählt werden, das zur Selektion verwendet werden soll. Für jedes Attribut, das in Frage kommt, wird der Wert
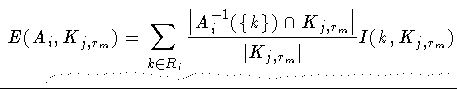
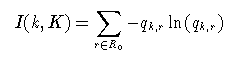
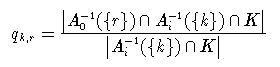
qk,r gibt also den Anteil der Tupel aus der Kategorie r unter den Tupeln des Knotens an, bei denen das Attribut Ai den Wert k annimmt. Der Entropiewert I(k,K) gibt damit an, wie durchmischt die Tupel des Knotens in Bezug auf das Attribut A0 , also in Bezug auf die gesuchte Kategorisierung, sind.
Es wird das Attribut zur Selektion gewählt, bei dem der Wert E(Ai,Kj,rm) minimal ist, bei der die Kindknoten also bezüglich der gesuchten Kategorie möglichst wenig durchmischt sind.
Die Auswahl der Optimierungsheuristik ist folgendermaßen
motiviert: Betrachtet man die Beispiele eines Knotens als
Informationsquelle über die Zugehörigkeit zu den
Zielkategorien, dann gibt Formel (
4.2.4.2.2
)
eine Abschätzung des Informationsgehalts bzw. der Entropie eines
Kindknotens an, d. h. des mittleren Informationsgewinns, den das
Inspizieren eines Beispiels aus der Menge bringt. Sind fast alle
Beispiele der Knotenmenge aus einer Kategorie, ist der zu erwartende
Informationsgewinn gering. Sind sie sogar alle aus einer Kategorie, ist
entweder
qk,r=0 oder qk,r=1 und damit
|
|
|
|