



|
|
|
|
Der durch die Autoren durchgeführten Evaluierung liegen Datensätze für 4 Monate aus dem Bereich New York City zugrunde. Jeder Datensatz wurde durch 31 Attribute beschrieben, darunter Telefonnummer des Anrufenden, Länge des Gesprächs, Ursprungs- und Zielort und "long distance carrier". Weitere Attribute werden von den Autoren aus Sicherheitsgründen nicht mitgeteilt. Aus diesen Basisattributen wurden weitere Attribute abgeleitet, bzw. durch Generalisierungen der Wertebereiche Wissen hinzugefügt. So wurde das oben erwähnte Attribut TIME-OF-DAY mit den Werten: Morning, Afternoon, Twilight, Evening und Night konstruiert und ein binäres Attribut TO-PAYPHONE eingeführt, der unterscheidet ob es sich bei dem angrufenen Telefon um einen öffentlichen oder einen privaten Anschluss handelt.
Die Beispielmengen wurden - wie oben eingeführt - in einzelne Tage zerlegt. Ziel war es für einen Tag vorherzusagen, ob er Datensätze von betrügerischen Verbindungen enhält.
Die Daten wurden nach einer Reihe von Plausibilitätsüberlegungen bereinigt, so wurden z. B. solche Datensätze entfernt, die eine Zielrufnummer hatten, die sowohl in als missbräuchlich gekenntzeichneten Datensätzen auftrat, als auch ausserhalb dieser Datensätze. Es wurde nur bei solchen Tagen angenommen, dass sie Missbrauch enthalten, bei denen mindestens Gespräche mit einer Gesamtdauer von fünf Minuten als missbräuchlich gekennzeichnet wurden.
Um die assoziativen Regeln zu generieren und auszuwählen wurden 879 verschiedene Telefonkennungen mit mehr als einer halben Million Anrufdatensätzen verwendet. Ca. 3600 Kennungen wurden für die Profilierung, zum trainieren und testen ausgwählt. Die einzige Bedingung an diese Beispielsammlungen war, dass sie mindestens 30 missbrauchsfreie Tage enthalten mussten, die für das Profilierung benutzt wurden. Aus den übrigen Daten wurden ca. 96000 Datensätze für jeweils einen Tag zusammengestellt, aus denen per Zufall 10000 als Trainingsset und 5000 als Testset verwendet wurden. Dabei wurden Trainingsset und Testset nach Kennungen getrennt, sodass kein Datensatz einer Kennung, die im Training verwendet wurde, im Test auftreten konnte. Die beiden Mengen wurden so gewählt, dass jeweils 20% der Tage missbräuchliche Verbindungen enthielten. Im ersten Schritt wurden 3630 assoziative Regeln gefunden, die für mindestens zwei Kennungen zum entsprechenden Grad gültig waren. Daraus wurden 99 ausgewählt, die die verschiedenen Kennungen gut genug abdeckten. Auf diese Regeln wurden zwei Monitor - Templates angewendet, sodass 198 einzelne Monitore in den Lernschritt einbezogen wurden. Bei der Vorwärtsselektion zur Konstruktion der linearen Schwellwertfunktion wurden schließlich elf Monitore ausgewählt und zu einem Missbrauchsdetektor kombiniert.
Der so erzeugte Missbrauchsdetektor wurde mit einer Reihe anderer Detektoren bzw. Verfahren verglichen. Dazu wurde die Trefferquote also der Anteil der richtig beurteilten "Tage" berechnet. Zusätzlich berechneten Fawcett und Provost noch eine Kostenfunktion bei der sie einen falschen Alarm, also die irrtümliche Annahme ein Telefon sei geklont worden, mit Kosten von 5 $ ansetzten und für jede Minute der unerkannt missbräuchlich geführten Gespräche Unkosten von 40 Cent berechneten.
"Alarm on all" und "Alarm on none" sind die einfachsten Strategien, die immer oder nie auf Missbrauch schließen und damit wegen der 20 / 80 Verteilung eine Trefferrate von 0.2 bzw. 0.8 haben. Die Kosten belaufen sich auf 20000 $ bzw 18111 $.
"Collision und Velocities" war ein Detektor, der die oben beschriebenen gleichzeitigen Anrufe, bzw. Anrufe von weit auseinanderliegenden Orten in kurzen Zeitabständen untersucht. Neben einzelnen Fehlern durch falsche Zeitmessung in unterschiedlichen Zellen des Netzes, wurden hier vor allem viele Tage mit Missbrauch nicht entdeckt. Die Trefferrate lag für diesen Detektor bei 0.82, die berechneten Kosten bei 17578 $
Dem "High Usage" Detektor lag die Annahme zugrunde, dass das Klonen vor allem durch eine starke Zunahme der Gespräche auffallen sollte. Er wurde im wesentlichen als ein Monitor auf der Basis der Gesamtkosten pro Tag mit dem Monitor - Template, das die Abweichung vom Mittelwert in Standardabweichungen angibt implementiert. Die Schwelle wurde empirisch ermittelt. Die Trefferquote lag bei 0.88, die Kosten bei 6938 $
Im "Best Individual Monitor" wurde der beste einzelne
Monitor, der nach dem oben beschriebenen Verfahren gefunden wurde,
verwendet. Er basiert auf der Regel:
(TIME-OF-DAY=EVENING) 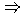 FRAUD. Durch die Profilierung misst
dieser Monitor starke Veränderungen im Verhalten. D. h. nicht
häufiges telefonieren am Abend wurde als Indikator für
Missbrauch gefunden, sondern eine starke Zunahme der Telefonate am Abend
(das war bei 119 Telefonkennungen der Fall). Die Trefferquote lag bei
0.89, die Kosten bei 7940
$
FRAUD. Durch die Profilierung misst
dieser Monitor starke Veränderungen im Verhalten. D. h. nicht
häufiges telefonieren am Abend wurde als Indikator für
Missbrauch gefunden, sondern eine starke Zunahme der Telefonate am Abend
(das war bei 119 Telefonkennungen der Fall). Die Trefferquote lag bei
0.89, die Kosten bei 7940
$
Der "State of the Art" Detektor bestand aus 13 "von Hand" konstruierten Monitoren, die auf die Daten angewendet wurden und jeder einzeln Missbrauch erkennen sollte. Neben "collision und velocity" Monitoren wurden die angerufenen Nummern bzw. die Orte an denen sie sich befanden ("bad cellsites") und die Abweichung in der täglichen Benutzung verwendet. Diese Monitore waren in einer Voruntersuchung als die besten Einzeldetektoren ermittelt worden. Sie wurden mit der gleichen Gewichtungsmethode zu einer linearen Schwellwertfunktion zusammengesetzt, wie die automatisch ausgewählten Monitore. Die Trefferquote lag bei 0.90, die Kosten bei 6557 $.
Im Vergleich zu diesen Systemen erreichte der automatisch erzeugte Detektor eine Trefferquote von 0.92 bei Kosten von 5403 $ und damit das beste Ergebnis. Auch eine Kombination mit dem "State of the Art" Detektor verbesserte dieses Ergebnis im Bezug auf die Trefferquote nicht. Allerdings fielen die berechneten Kosten mit 5078 $ geringer aus.
Mit der Kostenfunktion ergibt sich eine ähnliche Rangfolge unter den betrachteten Detektoren. Lediglich der "best individual monitor" liegt bei den Kosten deutlich höher als der "high usage" Detektor und die Kombination aus dem "state of the art" Detektor und dem in der Untersuchung konstruierten Detektor ist kostengünstiger als der Einsatz des automatisch konstruierten Detektors alleine. Die Ergebnisse sind in Abbildung 68 zusammengefasst.
 Abb. 68: Vergleich der unterschiedlichen Missbrauchsdetektoren (nach Fawcett und Provost 1997)
Abb. 68: Vergleich der unterschiedlichen Missbrauchsdetektoren (nach Fawcett und Provost 1997) |
|
|
|