



|
|
|
|
Ähnlich wie bei der Bestimmung von ähnlichen Wörtern beim zweisprachigen Retrieval, können Kookurrenzverfahren auch dazu benutzt werden, zu Wörtern der natürlichen Sprache ähnliche Deskriptoren aus einem kontrollierten Vokabular zu bestimmen. In einem Experiment von Ferber (1997) [->] wurde dazu eine Sammlung von 81 326 Einträgen aus der Idis Datenbank der British Library for Development Studies (BLDS) verwendet, die Verweise auf Artikel und Publikationen über die Entwicklung in der sogenannten dritten Welt enthält. Die Einträge enthalten neben weiteren Angaben den Titel eines Artikels und eine Indexierung mit dem OECD Thesaurus. Ein Beispiel ist in Abbildung 80 angegeben.
 Abb. 80: Datensatz aus der Idis Datenbank
Abb. 80: Datensatz aus der Idis DatenbankDie Untersuchung hatte zum Ziel, aus den Wörtern eines Titels mit Hilfe einer Term-Term-Matrix die intellektuell vergebenen Thesaurusdeskriptoren vorherzusagen. Die Term-Term-Matirx enthielt dabei Ähnlichkeiten zwischen Wörtern aus den Titeln und den Deskriptoren. Um die besten Deskriptoren für einen Titel zu bestimmen, wurde aus dem Titel ein Vektor erzeugt, in dem die Häufigkeiten der Terme im Titel eingetragen wurden. Dieser Vektor wurde mit der Ähnlichkeitsmatrix multipliziert, wodurch sich ein Vektor mit Gewichten über der Menge der Deskriptoren ergab. Nach diesen Gewichten wurden die Deskriptoren in eine Rangfolge gebracht, in der die besten Deskriptoren auf den ersten Plätzen stehen sollten. Diese Rangfolge kann mit Precision und Recall Maßen mit den intellektuell vergebenen Deskriptoren verglichen werden.
Im einzelnen wurde folgendermaßen vorgegangen: Zunächst wurden aus allen Titeln und Deskriptoren zwei Vokabulare bestimmt: das Vokabular der Titelwörter bestand aus den 3746 Wörtern die häufiger als 15 mal auftraten, aus mehr als zwei Buchstaben bestanden, mindestens einen Vokal enthielten und nicht nur aus "i" und "v" bestanden (also als einfache römische Zahlen interpretiert werden konnten). In das zweite Vokabular wurden die 3631 Deskriptoren aufgenommen, die mindestens zweimal auftraten.
Abb. 81: Mittlere Precision Werte bei einem Recall von 0.75 für unterschiedliche Werte der Parameter x und y.Aus der Sammlung der Einträge wurden zwei Teilsammlungen von jeweils 500 Einträgen als Trainings- und Testmengen zufällig ausgewählt. Aus den übrigen Einträgen wurden für alle Paare aus einem Titelterm und einem Deskriptorterm bestimmt, wie oft sie zusammen in einem Eintrag auftraten. Die Enträge enthielten im Mittel 8.44 Terme aus dem Vokabular der Titel (Standardabweichung: 4.57) und 5.30 Terme aus dem Deskriptorvokabular (Standardabweichung: 2.18). Zur Berechnung der Ähnlichkeiten zwischen den Termen der beiden Vokabulare wurde die Formel
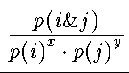
Zur Optimierung der Parameter wurden insgesamt mehr als 300 Durchgänge mit den 500 Trainingsbeispielen berechnet, bei denen x zwischen 0.3 und 1.5 und y zwischen 0.3 und 1.0 variiert wurde. Dabei wurden 6 verschiedene Gütemaße berechnet: mittlere Precisionwerte an den Recallwerten 0.25, 0.5, 0.75 und 1.0, sowie der Median und das arithmetische Mittel der Rangplätze der intellektuell vergebenen Deskriptoren. Ergebnisse für verschiedene Parameterwerte für die Precision bei einem Recall von 0.75 sind im Diagramm in Abbildung _81_ dargestellt. Abbildung 6.1.4 zeigt eine Tabelle mit den besten Werten für die verschiedenen Gütemaße, dabei sind auch die Ergebnisse, die mit der Testmenge erreicht wurden, eingetragen. Es zeigt sich, dass diese Ergebnisse sich nicht sonderlich von denen der Trainingsmenge unterscheiden, dass also durch die Optimierung der Parameter das Modell nicht nur auf die Beispiele der Trainingsmenge optimiert wurde.
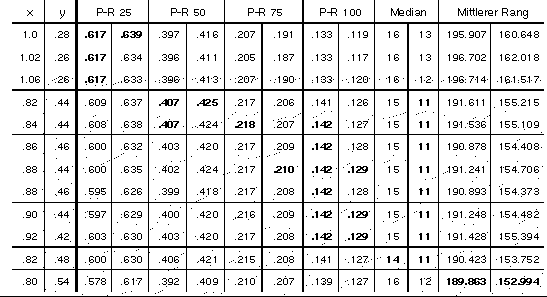
Jede Zeile zeigt alle 6 Gütemaße für ein Parameterpaar. Die Werte, die die besten für ein Maß auf der entsprechenden Menge in allen berechneten Durchgängen sind, sind fett gedruckt. Für jedes Maß sind links die Ergebnisse auf der Trainingsmenge und rechts die auf der Testmenge angegeben.
In allen Fällen - außer bei den Precisionwerten bei Recall 0.75 und 1.0 - sind die Ergebnisse auf der Testmenge besser als die auf der Trainingsmenge. Das zeigt, dass die Optimierung der Parameter das Modell verbessert und nicht nur an eine bestimmte Trainingsmenge anpasst. Die schlechteren Ergebnisse bei hohem Recall können durch Ausreißer mit sehr schlechten Rangplätzen erzeugt sein. Darauf deutet auch die Tatsache hin, dass die arithmetischen Mittel der Rangplätze soviel größer sind als die Mediane.
Ein interessanter Teilaspekt der Untersuchung zeigt sich in der Tatsache, dass sich die Bereiche der Parameterwerte, in denen die besten Ergebnisse erzielt wurden, für x und y stark unterscheiden. x ist der Parameter, mit dem der Einfluss der Häufigkeit der Titelwörter gesteuert wurde, y erfüllt diese Rolle für die Thesaurusdeskriptoren. Die besten Ergebnisse ergeben sich also wenn bei den Titelwörtern seltene (und damit spezifische) Terme stark gewichtet werden, bei den Thesaurustermen aber eher häufige (also allgemeinere) Deskriptoren stark gewichtet werden. Betrachtet man die Untersuchung als eine Simulation der Vergabe von Deskriptoren durch Menschen, kann man das folgendermaßen interpretieren: beim Lesen der Titel wird auf seltene Wörter geachtet, vermutlich um die spezifischen Inhalte zu erkennen und zu berücksichtigen. Beim Vergeben der Deskriptoren werden eher häufige und damit allgemeinere Terme verwendet, vermutlich um das Thema des Artikels gut abzudecken und damit einen guten Recall sicherzustellen.
|
|
|
|