 |
| ||||||||||
2.6.3: Verfahren
Die Autoren verwenden ein mehrstufiges Verfahren, um einen Missbrauchsdetektor zu
erzeugen. Im ersten Schritt werden in den Datensätzen, die zu
einzelnen Telefonkennungen gehören, jeweils
assoziative Regeln für betrügerisches Verhalten mit einem Grad
gesucht, der größer als eine vorgegebene Schwelle ist.
Als Beispiel geben die Autoren an:
(TIME-OF-DAY = NIGHT) AND (LOCATION = BRONX)
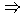 FRAUD
(
FRAUD
(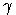 =0,89
).
Aus diesen für eine spezielle Kennung spezifischen
Regeln werden die allgemeinsten, deren Grad noch über der Schwelle liegt,
weiterverwendet. Das heißt, eine Regel, bei der noch eine weitere
Bedingung konjunktiv verknüpft würde (z.B.
(TIME-OF-DAY = NIGHT) AND (LOCATION = BRONX) AND (DAY-OF-WEEK = SATURDAY)
FRAUD (=0,93
)),
würde bei der weiteren Bearbeitung nicht berücksichtigt.
=0,89
).
Aus diesen für eine spezielle Kennung spezifischen
Regeln werden die allgemeinsten, deren Grad noch über der Schwelle liegt,
weiterverwendet. Das heißt, eine Regel, bei der noch eine weitere
Bedingung konjunktiv verknüpft würde (z.B.
(TIME-OF-DAY = NIGHT) AND (LOCATION = BRONX) AND (DAY-OF-WEEK = SATURDAY)
FRAUD (=0,93
)),
würde bei der weiteren Bearbeitung nicht berücksichtigt.
Nachdem für alle zu untersuchenden Telefonkennungen diese Regeln ermittelt wurden, stehen sehr viele, jeweils für eine Kennung spezifische Regeln zur Verfügung, aus denen geeignete Regeln zum Bau von Missbrauchsindikatoren ausgewählt werden können.
Dazu werden zwei Kriterien verwendet: Zum einen wird für jede einzelne Regel untersucht, bei wie vielen Kennungen sie in den Beispielmengen gefunden wurde. (Hier unterscheidet sich das Verfahren von klassischen einstufigen Lernverfahren, bei denen untersucht wird, wie viele einzelne Beispiele eine Regel abdeckt.) Zum anderen wird darauf geachtet, dass aus jeder Beispielmenge eine Mindestanzahl von Regeln in die Auswahl aufgenommen wird. Entsprechend wird die Auswahl durchgeführt:
Für jede Kennung wird zunächst untersucht, ob bereits die vorgegebene notwendige Mindestanzahl von Regeln aus der zugehörigen Beispielmenge in der Auswahl vorhanden ist. Ist das nicht der Fall, werden die Regeln gemäß ihrer Häufigkeit in der Gesamtmenge in eine Rangfolge gebracht. Beginnend mit der häufigsten Regel werden so lange Regeln in die Auswahl übernommen, bis die vorgegebene Anzahl von Regeln für die Kennung erreicht ist.
Die Regeln dieser Auswahl werden im nächsten Schritt an die spezifischen Eigenschaften (Profile) der Daten der einzelnen Kennungen angepasst. Dazu werden Kenngrößen verwendet, die die Eigenschaften möglichst gut charakterisieren und damit einen Missbrauch gut erkennbar machen sollen. Die Werte der Kenngrößen werden auf dem Teil der Beispieldatensätze einer Kennung ermittelt, die die legale Benutzung beschreiben. Dieser Schritt wird auch Profilierung (profiling) genannt. Dazu wurden im aktuellen Beispiel jeweils die Daten eines Tages zusammengefasst. In der Regel wird dann die Anzahl der Datensätze betrachtet, die die Bedingungen einer bestimmte Regel erfüllen und daher auf Missbrauch schließen lassen.
Es können verschiedene "Rezepte" (auch Monitor-Templates genannt) für solche Kenngrößen angeboten werden. So kann z.B. das Maximum der Anzahlen legaler Beispiele, die pro Tag von einer Regel erfasst werden, als Kenngröße gewählt werden. Werden an einem Testtag mehr Beispiele von der Regel erfasst, deutet das auf Missbrauch hin. Der binäre Monitor würde in diesem Fall den Wert 1 liefern, während er sonst (wenn die Maximalzahl nicht überschritten wird) eine 0 liefert. Andere Verhaltensparameter wären z.B. der Mittelwert und die Standardabweichung der Anzahl der Beispiele, die die Regel erfüllen. Ein reellwertiger Monitor, der auf diesen Parametern basiert, könnte angeben, um das Wievielfache der Standardabweichung der aktuelle Wert eines Tages über dem Mittelwert liegt.
Die Autoren verwenden verschiedene Monitor-Templates und konstruieren für jedes Paar aus einem Template und einer Regel einen Monitor. Nach diesem Schritt stehen für jede Kennung eine Reihe von an die legalen Nutzungsdaten angepassten Monitoren zur Verfügung. Diese Monitore werden mit Methoden, wie sie in Abschnitt 2.3.9 über multivariate Entscheidungsbäume vorgestellt wurden, zu einem Missbrauchsdetektor zusammengefasst: Mit einer sequenziellen Vorwärtsauswahl werden die besten Monitore für eine lineare Schwellwertfunktion (LTU) herausgesucht und kombiniert.
Um einen neuen Detektor für einen neuen Kunden oder eine neue Kundin zu erzeugen, wird nur der Profilierungsschritt mit einem Satz von Beispielen durchgeführt, von denen sicher angenommen werden kann, dass er keine missbräuchlichen Anrufe enthält. Die Konstruktion der LTU einschließlich der Selektion der verwendeten Monitore kann nicht neu berechnet werden, da ja keine Daten zum Missbrauch vorliegen.
| Navigation | [ Zurück ] [ Inhalt ] [ Stichwörter ] [ Feedback ] [ Home ] |
| Position im Angebot | Information Retrieval -> Wissensgewinnung mit Data-Mining-Methoden -> Ein komplexeres Beispiel |
| Dieser Abschnitt und seine Unterabschnitte | ||||
| Inhalt | Stichwörter in der Reihenfolge ihres Auftretens | Stichwörter alphabetisch sortiert | ||
|
assoziative Regel, Profilierung, profiling, lineare Schwellwertfunktion, LTU | assoziative Regel, lineare Schwellwertfunktion, LTU, Profilierung, profiling | ||