3.2.2: Abschätzung des Retrieval-Status-Werts
Die Produktformel für die Wahrscheinlichkeit
unabhängiger Ereignisse und die bayessche Formel werden im
Folgenden verwendet, um mit vereinfachenden Annahmen die gesuchte
Wahrscheinlichkeit für die Beurteilung der Relevanz
eines Dokuments abzuschätzen. Sie kann jetzt
als bedingte Wahrscheinlichkeit geschrieben
werden. Dazu verwenden Fuhr und Buckley (1991)
[->]
und Fuhr (1995) [->]
das Ereignis
R
"Ein Dokument wird als relevant
eingeschätzt" und schreibt
P(R | q,d)
, also die
bedingte Wahrscheinlichkeit dafür, dass eine Relevanz
angegeben wird, unter der Bedingung, dass die Anfrage
q
und das Dokument
d
vorliegen.
Der zugrunde liegende
Grundraum ist das kartesische Produkt
G=D×Q×{R,NR}
, wobei
Q
die Menge aller Anfragen
und
R
bzw.
NR
die Beurteilung als
relevant bzw. nicht relevant
bedeuten. Die Schreibweise der Bedingung
mit einem Komma entspricht dem
Durchschnitt der Mengen, die durch geeignet
definierte Attribute mit diesen
Werten beschrieben werden können.
Sei
Ar:G->{R,NR}
das Attribut, das angibt,
ob ein Element aus dem Grundraum als relevant beurteilt wurde oder
nicht, und
Aq:G->Q
das Attribut, das die verwendete Anfrage
beschreibt, dann ist die
Bedingung
R,q=((Ar=R)
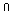 (Aq=q))
, also
die Menge der Elementarereignisse, bei denen ein Dokument
für die Anfrage
q
als relevant beurteilt wurde. (Aq=q))
, also
die Menge der Elementarereignisse, bei denen ein Dokument
für die Anfrage
q
als relevant beurteilt wurde.
Um die bedingte Wahrscheinlichkeit
P(R | q,d)
abzuschätzen, geht man zunächst wieder zu
einfacheren Repräsentationen von Dokument und Anfrage über:
als Menge der Terme, die in ihnen vorkommen, oder
als Vektoren aus binären Attributwerten, die das Auftreten eines Terms signalisieren.
Dazu sei
T={t1,...,tN}
die Menge der Terme, die in einer Dokumentensammlung
D
vorkommen.
Anfragen und Dokumente werden als Teilmengen q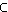 T
und dT
der Terme oder
als charakteristische Funktionen T
und dT
der Terme oder
als charakteristische Funktionen
| Ai |
(d) |
=
|
{ |
| 1 |
falls ti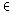 d d |
|
0 |
sonst |
|
dargestellt.
Neben der Wahrscheinlichkeit kann man als Maß für die Chance, dass ein Ereignis eintritt, den
Quotient seiner Wahrscheinlichkeit mit der Wahrscheinlichkeit des
Komplementärereignisses, die
Quote des Ereignisses
(odds) betrachten:
| O |
(X) |
= |
| p(
X) |
 |
| p(X-
) |
|
= |
| p(X)
|
|
| 1-p(X) |
|
Die Quote ist
<1
für Wahrscheinlichkeiten
<0,5
und
>1
für Wahrscheinlichkeiten
>0,5
. Sie ist streng
monoton, liefert also dieselbe
Rangfolge für Ereignisse wie die
Wahrscheinlichkeit. Sie erlaubt aber manchmal einfacheres
Rechnen.
Statt der gesuchten bedingten Wahrscheinlichkeit des gesuchten
Ereignisses "Es wird ein positives Relevanzurteil unter der Bedingung des Dokuments
d
und der Anfrage
q
abgegeben" wird nun
ihre Quote
| O |
(R | q,d) |
= |
| p(
R | q,d) |
|
| p(R- | q,d) |
|
abgeschätzt.
Zunächst folgt mit
| p |
(d | Rq) |
= |
|
und damit
p(Rq)·p(
d | Rq)=p(Rd
q)
| P |
(R | q,d) |
=
|
|
| = |
| p(d | Rq)
·p(Rq) |
|
| p(
d | q)·p(q)
|
|
| = |
| p(d | Rq)
·p(R | q) |
|
| p(
d | q) |
|
Es folgt also
| O |
(R | q,d) |
= |
| p(
R | q,d) |
|
| p(R- | q,d) |
|
= |
| p(d | Rq)
·p(R | q) |
|
| p(
d | q) |
|
|
| p(
d | R-q)
·p(R- | q)
|
|
| p(d | q) |
|
|
= |
| p(R | q)
|
|
| p(R- | q)
|
|
· |
|
p(d | R,q)
ist die
bedingte Wahrscheinlichkeit eines Dokuments
d
unter der Bedingung, dass es zur Anfrage
q
als relevant beurteilt wird.
Um diese Wahrscheinlichkeit zu schätzen,
müssten zu allen Anfragen Dokumente mit Relevanzbeurteilungen
vorliegen. Da diese Abschätzung aber in der Regel mit zu großem Aufwand
verbunden ist, wird die Berechnung
im nächsten Schritt auf die Terme heruntergebrochen. Dazu wird die
starke (und unrealistische) Annahme gemacht, dass
das Auftreten von Termen in Dokumenten unabhängig ist.
So ergibt sich (mit
I={1,...,N}
)
|
p |
(d | R,q) |
= p(
|
|
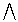 |
| iI |
|
(Ai=di) |
| R,q)
= |
|
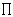 |
| iI |
|
p |
(
(Ai=di)
| R,q)
|
= |
|
|
| iI |
|
p |
(di | R,q) |
Für die Quote gilt dann:
| O |
(R | q,d) |
= |
| p(
R | q) |
|
| p(R-
| q) |
|
· |
| p(
d | R,q) |
|
| p(d | R-,q) |
|
=O |
(
R | q) |
· |
|
|
| iI |
|
| p((Ai=d
i) | R,q) |
|
| p((Ai=di)
| R-,q) |
|
Man kann die Unabhängigkeitsannahme etwas
abschwächen, indem man direkt annimmt,
dass
| p(d | R,q) |
|
| p(d | R-,q)
|
|
= |
|
|
| iI |
|
| p(
(Ai=di)
| R,q) |
|
| p((
Ai=di) | R-,q) |
|
(die so genannte
linked dependency
assumption) gilt.
Allerdings ist diese Annahme schwieriger zu
interpretieren.
Zur weiteren Vereinfachung wird angenommen, dass für alle
tiT\q
gilt, dass
p(Ai=di | R,q)
=p(Ai=di | R-
,q)
ist. Das bedeutet,
dass für alle Terme, die nicht in
der Anfrage genannt werden, die Wahrscheinlichkeit, dass sie in einem
relevanten Dokument auftreten, genauso groß ist wie die, dass sie
in einem nicht relevanten Dokument auftreten.
Um diese vereinfachende Annahme auszunutzen,
spaltet man das Produkt auf:
| O |
(R | q,d) |
=O |
(
R | q) |
· |
|
| p((Ai=
di) | R,q)
|
|
| p((Ai=di
) | R-,q)
|
|
|
| |
|
|
· |
|
| p((Ai=di
) | R,q) |
|
| p(
(Ai=di)
| R-,q) |
|
|
| |
|
|
· |
|
|
| {i
I | ti&nisin;q} |
|
|
p((Ai=di)
| R,q) |
|
| p((
Ai=di) | R-,q) |
|
Der letzte Faktor dieses Produkts
ist aufgrund der vereinfachenden Annahme gleich 1, kann
also weggelassen werden. Setzt man
ri=p(Ai=1 | R,q)
und
ni=p(Ai=1 | R-,q)
,
so kann man schreiben
| O |
(R | q,d) |
=O |
(
R | q) |
· |
|
| ri |
|
| ni |
|
· |
|
| 1-ri |
|
| 1-ni |
|
da
Ai
ja genau dann gleich 1
ist, wenn der Term
ti
im Dokument d
vorkommt, und sonst gleich 0
.
Da im ersten Produkt der Formel die Terme zusammengefasst sind,
die im Dokument d
vorkommen und im zweiten die, die nicht vorkommen, kann dort
zur komplementären Wahrscheinlichkeit
p(Ai=0 | R,q)=1
-ri
bzw. p(Ai=0 | R-
,q)=1-ni
übergegangen
werden.
Meistens geht es darum, verschiedene Dokumente in eine Rangfolge bezüglich einer
Anfrage zu bringen. Es interessieren also vor allem solche Faktoren
des Produkts, die sich bei verschiedenen Dokumenten
ändern. Um diese zu isolieren, kann man folgende Umformung
vornehmen, bei der ein Faktor
1
aufmultipliziert und geeignet aufgespaltet wird:
| O |
(R | q,d) |
=O |
(
R | q) |
· |
|
| ri |
|
| ni |
|
· |
|
| 1-ri |
|
| 1-ni |
|
·
|
|
| (1-ri)(
1-ni) |
|
| (1-
ni)(1-ri
) |
|
Durch geeignetes Umgruppieren der Produkte erhält man
| O |
(R | q,d) |
=O |
(
R | q) |
· |
|
| ri(1-ni)
|
|
| ni(1-ri)
|
|
· |
|
| 1-ri |
|
| 1-ni |
|
Berechnet man die Werte für
mehrere Dokumente
d
, so ist
lediglich der mittlere Faktor dieses Produkts
noch von den verwendeten Dokumenten
abhängig, also für die Bildung einer Rangfolge
relevant. Zur einfacheren Berechnung kann man auf
diesen Faktor noch einen Logarithmus anwenden, der als streng monotone
Funktion die Rangfolge nicht verändert.
So erhält man als Kenngröße eines Dokuments
d
den
Retrieval-Status-Wert
(retrieval status
value):
|
|
log |
|
ri(1-ni)
|
|
| ni(1-ri)
|
|
= |
|
| (log |
| ri |
|
| ni |
|
+log |
| (1-ni) |
|
| (1-ri) |
|
) |
Um das Verfahren anzuwenden, müssen Werte
für
ri
und
ni
geschätzt werden.
ri
ist die Wahrscheinlichkeit, dass der Term
ti
in einem für die Anfrage
q
relevanten Dokument vorkommt,
und
ni
ist die Wahrscheinlichkeit, dass der Term
ti
in einem für die Anfrage
q
nicht relevanten Dokument vorkommt.
Um die Werte zu
schätzen, kann eine Menge von
Dokumenten verwendet werden, für die
bekannt ist, ob sie für eine Anfrage relevant sind oder nicht.
Diese Information kann z.B. durch
Relevance
Feedback ermittelt werden,
also durch die Einschätzung der Relevanz der gefundenen Dokumente
durch die Nutzenden. Als Schätzung für
ri
kann man die Anzahl
reli
der relevanten Dokumente, die den Term
ti
enthalten, durch die Gesamtzahl
rel
der relevanten Dokumente teilen:
| ri~= |
| rel
i |
|
| rel |
|
Als Schätzung für
ni
kann man die Anzahl
nreli
der Dokumente, die nicht als relevant
eingeschätzt wurden und den Term
ti
enthalten, durch die Gesamtzahl
nrel
der nichtrelevanten Dokumente teilen:
| ni~= |
| nrel
i |
|
| nrel |
|
Bei dieser Schätzung ergeben sich besonders bei
kleinen Dokumentenmengen Probleme, wenn eine der relativen
Häufigkeiten 1 oder 0 ist. In diesen Fällen ist
entweder der Bruch oder der Logarithmus nicht definiert. Ist das nicht
der Fall, ergibt sich für den Retrieval-Status
der Schätzwert:
|
|
|
log
|
| reli |
|
| rel |
| (1- |
| nreli |
|
| nrel |
|
) |
|
| nreli |
|
| nrel |
| (1- |
| reli |
|
| rel |
|
) |
|
=
|
|
log |
|
reli(nrel-nreli)
|
|
| nreli(rel-reli)
|
|
=
|
|
| ( log |
| reli |
|
| (rel-reli) |
|
- log |
| nreli |
|
| (nrel-nreli) |
|
) |
Das heißt, ein Term
ti
trägt positiv zu der Summe bei, wenn seine
Quote, berechnet mit der relativen Häufigkeit, in relevanten
Dokumenten größer ist als in nicht relevanten Dokumenten.
Weiter folgt, dass ein neues
Dokument, das viele Terme enthält, die überproportional
häufig in relevanten Dokumenten aufgetreten sind,
einen hohen
Statuswert erhält.
Bei diesem Verfahren muss
zu jeder Anfrage zunächst
eine Menge von
Dokumenten auf ihre Relevanz bezüglich der Anfrage
beurteilt werden, damit anschließend
zusätzliche Dokumente bewertet werden können.
Das ist immer noch ein
aufwändiges Verfahren.
Eine Möglichkeit, dieses Verfahren zu verallgemeinern, besteht darin,
über verschiedene Anfragen zu mitteln, d.h. solche Terme hoch
zu gewichten, die in vielen Dokumenten viel zu der Summe des Status-Werts beitragen.
|

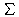
 Abbildung 73: Beispiele mit Relevanzangaben zur Schätzung des Retrieval-Status-Werts
zu einer Anfrage q = (t1,...,t6)
Abbildung 73: Beispiele mit Relevanzangaben zur Schätzung des Retrieval-Status-Werts
zu einer Anfrage q = (t1,...,t6)