3.1.2: Das Paice-Modell
Ganz ähnlich wie das MMM-Modell ist auch ein
Modell von Paice definiert, das ebenfalls von Fox, Betrabet, Koushik und
Lee (1992) [->]
im Buch von Frakes und Baeza-Yates (1992) [->]
beschrieben wird. Hier
steht allerdings mehr die Sicht als Ähnlichkeitsmaß im
Vordergrund. Auch hier werden die Anfrageterme nicht gewichtet, es gilt
also
qj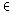 {0,1}
. Der Unterschied zum MMM-Modell besteht in
der Ähnlichkeitsfunktion, die nicht nur das Minimum und
Maximum einbezieht sondern auch - mit einer
geringeren Gewichtung - die Gewichte der anderen
Terme der Anfrage. Dazu werden für jeden Dokumentvektor die Gewichte der
Terme der Anfrage nach ihrer Größe geordnet. Das
kann durch eine Permutation
t:{1,...,n}->{
1,...,n}
festgehalten werden, bei der
t(1)
die Position des größten Gewichts im unscharfen
Schnitt des Anfragevektors mit dem Dokumentvektor angibt und
t(n)
die des kleinsten (bzw. eines kleinsten). {0,1}
. Der Unterschied zum MMM-Modell besteht in
der Ähnlichkeitsfunktion, die nicht nur das Minimum und
Maximum einbezieht sondern auch - mit einer
geringeren Gewichtung - die Gewichte der anderen
Terme der Anfrage. Dazu werden für jeden Dokumentvektor die Gewichte der
Terme der Anfrage nach ihrer Größe geordnet. Das
kann durch eine Permutation
t:{1,...,n}->{
1,...,n}
festgehalten werden, bei der
t(1)
die Position des größten Gewichts im unscharfen
Schnitt des Anfragevektors mit dem Dokumentvektor angibt und
t(n)
die des kleinsten (bzw. eines kleinsten).
Als Ähnlichkeitsmaß wird dann die Formel
|
| s(wi,q)= |
| |supp(Q)| |
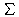 |
| j=1 |
| cj-1wi,t(j) |
 |
|
|
| |supp(Q)| |
|
| j=1 |
|
cj-1 |
|
mit
c[0,1]
verwendet, wenn
eine
OR-Anfrage gestellt werden soll. Dabei bezeichnet
|supp(Q)
|
den Träger der Anfrage, also die Terme, die in
der Anfrage vorkommen und deren Wert in q
deshalb gleich
1
ist. Für eine AND-Anfrage wird als Koeffizient im
Zähler
c|supp(Q)|-j
verwendet.
In dieser Ähnlichkeitsformel werden
im ersten Fall die größten Gewichte von Anfragetermen
im Dokumentvektor am stärksten
gewichtet, im zweiten
die kleinsten. Nun fragt sich, ob die zusätzliche
Gewichtung der sowieso schon unterschiedlich großen Gewichte
notwendig ist. Tatsächlich berichten Fox, Betrabet, Koushik und
Lee (1992) [->]
, dass
sich bei experimentellen
Untersuchungen für AND-Anfragen die
besten Ergebnisse für c=1
ergeben
haben, also für den Fall, in dem keine zusätzliche Gewichtung der Gewichte vorgenommen wurde und
sich die Ähnlichkeitsformel auf
| s |
(wi,q) |
=
|
| n |
|
| j=1 |
| qjwi,j |
|
| |supp(Q)| |
|
also das Skalarprodukt dividiert durch die Anzahl der
Anfrageterme reduziert.
Für OR-Anfragen berichten die Autoren von besten Ergebnissen für
den Wert c=0,7
, also für den Fall, in
dem große Gewichte zusätzlich verstärkt werden.
|
