3.4.1: Die TREC-3-Ergebnisse von SMART
Ein solches Verfahren wurde z.B. von
Buckley, Salton, Allan und Singhal (1995) [->]
mit
dem SMART-Retrieval-System für TREC-3
verwendet. In einer einfachen Version wurden die Dokumentvektoren
aufgrund von Termen und Termpaaren
konstruiert. Die Terme wurde durch eine Stoppwortliste und eine
lexikografische Stammformenreduktion bestimmt.
Termpaare wurden zur Indexierung zugelassen, wenn sie in
mindestens 25 Dokumenten der TREC-1 Sammlung vorkamen.
Die Gewichtung der Terme in einer Anfrage
wurde mit der Formel
| wi,k= |
| (ln
(h(i,k))+
1,0)·ln(m/d(
k)) |
 |
| | ( |
| n |
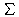 |
| j=1 |
| [
(ln
(h
(i,j)
)
+1,0)
·ln
(m/d
(j))
]
2
|
)1/2 |
|
|
berechnet, wobei
h(i,k)
die Häufigkeit des Terms
tk
im Dokument bzw. der Anfrage
i
bezeichnet,
m
die Anzahl der Dokumente,
n
die Anzahl der Terme und
d(k)
die Anzahl der Dokumente, die den Term
tk
enthalten. Für die
Termpaare wurde die gleiche Formel verwendet, wobei im Nenner aber wieder nur
über die Terme summiert wurde. Zur Berechnung der Gewichte in
Dokumentvektoren wurde in der Formel der IDF-Faktor weggelassen.
Als Ähnlichkeitsfunktion für die so normierten Vektoren wurde
das Skalarprodukt verwendet, insgesamt also das Cosinus-Maß.
Zur Veränderung des Anfragevektors
wurde ein leicht modifiziertes Rocchio-Verfahren mit den 30
besten Antwortdokumenten verwendet (zumindest kann der
Aufsatz so interpretiert werden):
Alle Terme und Termpaare aus diesen Dokumenten
wurden gemäß ihrer Häufigkeiten in diesen
30 Dokumenten sortiert. Dann wurden die 500 häufigsten Terme und die
10 häufigsten Termpaare ausgewählt.
Die 30 Dokumentvektoren wurden auf diese Terme
und Termpaare eingeschränkt und gemäß der Rocchio-Formel
mit den Parametern
(8,8,0)
zum Anfragevektor addiert.
Es wurden also der ursprüngliche
Anfragevektor und das Mittel der auf die 510 Komponenten projizierten 30
Dokumentvektoren gleich gewichtet. Es wurden keine "nicht
relevanten Dokumentvektoren" abgezogen.
In einem etwas komplizierteren Ansatz wurden
nicht die vollständigen Dokumente
verwendet, um den Query-Vektor zu verbessern,
sondern es wurde versucht, in den Dokumenten
besonders relevante Passagen zu finden, mit
denen der Query-Vektor optimiert werden kann.
Dazu wurden die Dokumente in sich um 100 Wörter
überlappende Blöcke oder "Fenster" von jeweils 200
Wörtern Länge zerlegt, aus denen dann
Vektoren mit Einträgen aus
{0,1}
gebildet wurden, die nur angeben, ob ein
Term oder ein Termpaar in dem entsprechenden Block auftritt (1) oder
nicht (0). Als Ähnlichkeitsmaß wurde die Formel
|
| s(wi,q)=w
i·q(1+2 |
|
|
|
| max |
b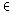 Bd Bd |
|
(b·q) |
|
|
|
|
| max |
| bBD |
|
(b·q) |
|
) |
verwendet, wobei
Bd
die Menge der Vektoren bezeichnet, die aus den Blöcken
des Dokuments
dD
gebildet werden.
BD
gibt entsprechend die
Menge aller Vektoren an, die
aus allen Blöcken sämtlicher Dokumente einer Dokumentensammlung
D
gebildet werden können. Bei der praktischen
Durchführung wurde dieses Maximum nur über die Teilmenge der
Dokumente bestimmt, die in einem ersten Schritt für das Feedback
ausgewählt wurden.
Die konkrete Berechnung wurde in folgenden Schritten
durchgeführt:
- In einer Ähnlichkeitssuche wurden die besten 1 750 Dokumente zu
einer Anfrage q
bestimmt.
- Für jedes einzelne dieser Dokumente wurde
- die Menge Bd
der Textblöcke erzeugt,
- zu jedem Textblock ein Vektor bBd
erzeugt,
- die Ähnlichkeit bd·q
dieses Vektors bBd
zur
Anfrage q
berechnet,
- das Maximum
|
| max |
| bBd |
|
(b·q) |
dieser Ähnlichkeitswerte über alle
Blöcke ermittelt.
- Über alle 1 750 Dokumente der Ergebnismenge
Dq1750
wurde das Maximum der Maxima
|
maxdDq1750
{max
bBd(b·q))=maxbBDq1750
(b·q)
|
mit | BD= |
|
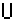 |
| dD
q1750 |
|
Bd |
berechnet.
- Mit der Ähnlichkeitsfunktion s
wurden
die Ähnlichkeiten der 1 750 Dokumente zum
Anfragevektor q
berechnet.
- Die Dokumente wurden nach diesen Ähnlichkeitswerten in eine
Rangfolge gebracht und die besten 1 000 ausgegeben.
Die Ergebnisse der beiden
Methoden wurden mit der "einfachen" Ähnlichkeit (siehe
Abbildung 80
) und mit den anderen TREC-3
Ergebnissen (siehe Abbildung 81
)
verglichen. Es zeigt sich, dass durch beide Verfahren Verbesserungen erreicht
werden können, wobei die erste Methode mehr den Recall verbessert,
während die zweite eher zu besseren Precision-Werten
führt. Das ist nicht erstaunlich, da bei
der ersten ja ganze Dokumente und damit eher thematisch breite
Texteinheiten, bei der zweiten aber kleine und damit eher thematisch
spezifische Texteinheiten für die Erweiterung der Anfrage verwendet
wurden.
|

 Abbildung 80: Ergebnisse der SMART-Verfahren in TREC 3
Abbildung 80: Ergebnisse der SMART-Verfahren in TREC 3