3.4.2: Die TREC-4-Ergebnisse von SMART
Bei der Bewertung des SMART-Systems mit Volltextdokumenten insbesondere
aus TREC-3 hatte sich gezeigt, dass die
Verwendung des Cosinus als Ähnlichkeitsmaß kurze Dokumente bevorzugt.
Um diese allgemeine Beobachtung zu überprüfen wurden die
TREC-4-(Trainings-)Dokumente nach ihrer Länge
sortiert und diese Rangfolge in 568 Mengen zu je 1 000 Dokumenten
unterteilt. (Entsprechende Angaben für TREC-3 finden
sich in Singhal, Buckley und Mitra, 1996
[->]
.) Für
jede Menge wurde der Median der Länge (in Byte) der darin
enthaltenen Dokumente berechnet. Für jeden TREC-4-Topic wurden
die 1 000
ähnlichsten Dokumente mit dem Cosinus-Maß ermittelt und
festgestellt, in welcher der Mengen sie auftraten.
Weiter wurde festgestellt, in welcher der Mengen die relevanten Dokumente auftraten.
Damit wurden für jede der durch die unterschiedlichen Längen charakterisierten Mengen zwei
relative Häufigkeiten berechnet: die relative Häufigkeit der gefundenen Dokumente und die
relative Häufigkeit der relevanten Dokumente. Diese beiden Werte können für die verschiedenen
Längenmediane verglichen werden (siehe Abbildung 82
).
Bei den mit dem Cosinus-Maß gefundenen Dokumenten zeigt sich eine leicht erhöhte relative Häufigkeit
für mittellange und sehr kurze Dokumente: Sie werden mit dem Cosinus-Maß eher als zu
einer Anfrage relevant eingeschätzt. Bei den (nach der Beurteilung der Experten)
relevanten Dokumenten zeigt sich ein klarer Anstieg ihrer relativen Häufigkeit mit
dem Median der Dokumentlänge:
Die Wahrscheinlichkeit, als zu einer Anfrage relevant beurteilt zu werden,
nimmt mit der Länge eines Dokuments zu.
Bei den TREC-3-Daten findet sich zwar auch
für die relative Häufigkeit, mit dem Cosinus-Maß gefunden
zu werden, ein leichter Anstieg mit dem Median der Länge,
aber der mittlere Anstieg mit wachsender Länge ist bei der relativen
Häufigkeit der Relevanz größer.
Es ist nahe liegend, für ein gutes Ähnlichkeitsmaß zu verlangen, dass
die beiden relativen Häufigkeiten für Dokumente gleicher
Länge möglichst gleich sein sollten. Damit wird eine
mögliche Fehlerquelle ausgeschlossen. Deshalb wurde für SMART bei
TREC-4 eine neue Normierung der
Dokumentvektoren entwickelt.
Sie geht zunächst (wie in Singhal, Buckley und Mitra, 1996
[->]
beschrieben) davon aus, dass die beiden Kurven der relativen Häufigkeiten
für die verschiedenen Längenmediane möglichst zur
Deckung gebracht werden sollen bzw. deren Abstand (in einem
geeigneten Maß) minimiert werden soll. Dazu wird eine
Transformation in Form einer Geradengleichung gesucht, die aus der alten Normierung (also
der euklidischen Länge des Vektors) eine neue Normierung berechnet, die den (mittleren)
Abstand der beiden Kurven verkleinert.
Diese Geradengleichung kann durch einen Punkt
(p,p)
(an dem sich die Normierung nicht ändern soll) und eine Steigung
m
(um die die Steigung der Normierung
"gekippt" werden soll) angegeben werden. Der
neue Normierungswert
y
hängt dann mit dem alten
x
folgendermaßen zusammen:
Diese Formel wird nun benutzt, um die
Normierung - also den Nenner der Gewichtsformel (174
) - zu
verändern. Durch Einsetzen erhält man
| wi,k= |
| w'(i,k)
|
 |
| mx+p(1-m) |
|
=p |
(1-m) |
| w'(
i,k) |
|
|
| 1+ |
| m |
|
| p(1-m) |
|
x |
|
wobei
w'(i,k)
für den Zähler
und
x
für den Nenner der
Gewichtsformel (174
)
steht. Da der Faktor
p(1-m)
für feste Parameter
p
und
m
für alle Vektoren konstant ist (und
damit die Rangfolge der Ähnlichkeiten nicht verändert), kann
man
| c:= |
| m |
|
| p(1-m) |
|
als einzigen Parameter der neuen Gewichtsformel betrachten und
mit Hilfe einer Beispielsammlung optimieren.
In TREC-4 wurde allerdings eine etwas
andere Gewichtungsformel verwendet. Sie lautet (soweit sich
das aus dem Text entschlüsseln lässt):
| wi,k= |
| 1+ln(h(i,k)) |
|
| 1+ln(h) |
|
/ ( |
(1-m) |
p+m·t |
(i) |
) |
wobei
h
die mittlere Termhäufigkeit
(
|
h= |
| 1 |
|
| |D|·n |
|
|
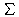 |
d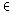 D D |
|
| n |
|
| k=1 |
|
h |
(d,k) |
) und
t(i)
die Anzahl verschiedener Terme im Dokument
di
angibt. Die Parameter
m
und
p
wurden auf
m=0,2
und die mittlere Anzahl verschiedener Terme
gesetzt.
Die Parameter aus TREC-3 wurden verändert, vor
allem um den kürzeren Topics Rechnung zu
tragen: Statt der besten 30 wurden nur noch die
besten 20 Dokumente für das Feedback verwendet. Bei der Expansion wurden
lediglich 50 Terme und 10 Termpaare verwendet.
Ansonsten wurde das Vorgehen aus
TREC-3 beibehalten. Die Ergebnisse sind in
Abbildung 83
dargestellt.
In einem zweiten Ansatz wurde eine weitgehend neue Ähnlichkeitsfunktion entwickelt
- das so genannte
Individual-Term-Locality-Maß
(ITL-Maß) - ,
mit der die besten Dokumente nach einer ersten
Ähnlichkeitssuche nochmals mit der Anfrage verglichen und in eine
Rangfolge gebracht werden.
Das Prinzip des ITL-Maßes scheint es zu
sein, zu jeder Position im Dokument, an der ein Anfrageterm
auftritt, Eigenschaften des Terms, der Sicherheit, mit der er gefunden
wurde, und der Umgebung durch Attribute zu erfassen. Diese Attributwerte werden zu einem Tupel zusammengefasst.
Für verschiedene Punkte in einem Dokument wird aus
diesen Tupeln ein Ähnlichkeitswert berechnet, indem sie
zunächst nach ihrem Abstand zum Untersuchungspunkt sortiert und
dann in dieser Sortierung abgearbeitet werden. Dabei wird
jedem Tupel in Abhängigkeit von seinen Eigenschaften ein Wert
zugeordnet; diese Werte werden aufaddiert und als Ähnlichkeit der
Anfrage zum Dokument im untersuchten Punkt verwendet. Die
größte Ähnlichkeit in einem untersuchten Punkt wird als
Ähnlichkeit des Dokuments zur Anfrage benutzt.
Die zur Berechnung des Werts eines Tupels verwendeten
Eigenschaften sind:
- der Abstand des Tupels von dem Punkt, an dem untersucht wird,
- die Häufigkeit, mit der der Term für den aktuellen Punkt
bereits gefunden wurde,
- das Gewicht des Terms in der Anfrage,
- die Sicherheit, mit der der Term gefunden wurde. (Das kann z.B. bei
Texten, die mit einer Texterkennungs-Software erfasst wurden, wichtig
sein oder auch bei Wörtern mit mehreren möglichen
Stämmen);
- die Gesamtlänge des Dokuments,
- die Beziehungen eines Terms zu den Termen, die ihn umgeben. Durch
solche Beziehungen kann z.B. berücksichtigt werden,
- ob die umgebenden Terme auch in der Anfrage dicht beieinander
auftauchen,
- ob die umgebenden Terme auch in einer Menge relevanter Dokumente
dicht beieinander auftauchen.
Als weitere, bisher nicht genutzte mögliche Beziehungen zwischen Termen nennen die
Autoren:
- ob die umgebenden Terme im selben Satzteil stehen,
- ob eine semantische Beziehung zwischen den umgebenden Termen
besteht.
Der maximale Wert, den ein Punkt bei der Summation erhält, wird
als Ähnlichkeitswert des Dokuments zur Anfrage verwendet.
Der Vorteil dieses Maßes scheint zu sein, dass ein
Dokument jeweils von vielen Punkten aus betrachtet wird und damit
verschiedene "relative Perspektiven" auf das Dokument
einbezogen werden können.
Zur Berechnung der zweiten
Serie von Ergebnislisten mit dem ITL-Maß wurde in TREC-4 auf den Ergebnissen der ersten
Serie aufgesetzt. Als Ergebnis der ersten Serie standen je Anfrage
20 am besten bewertete Dokumente,
eine durch Feedback erweiterte Anfragen und
eine Rangfolge von 1 750 Dokumenten zu
Verfügung. Für diese 1 750 Dokumente wurden mit dem ITL-Maß
die Ähnlichkeiten zu den erweiterten Anfragen berechnet.
Dabei wurden die 20 am besten bewerteten Dokumente mit
herangezogen. In jedem Dokument wurden an allen Stellen, an denen Terme
aus der Anfrage gefunden wurden, die Punktähnlichkeiten berechnet.
Als Ähnlichkeit des Dokuments zur Anfrage wurde die
Summe aus dem größten dieser Ähnlichkeitswerte und der
Ähnlichkeit aus der ersten Serie verwendet.
Die Ergebnisse der beiden SMART-Läufe sind in den Abbildungen 84
und 85
dargestellt. Die erste Serie liefert sehr gute Ergebnisse
für die kurzen TREC-4-Anfragen. Sie ist die beste vollautomatische Serie von
allen teilnehmenden Systemen. Die Ergebnisse der ITL-Serie sind um etwa 4%
schlechter. Das heißt, dass die von den Autoren vermuteten
Vorteile der ITL-Methode zumindest in dieser Untersuchung nicht
eingetreten sind. Im Gegenteil, durch
die nachgeschaltete ITL-Bewertung werden die guten Ergebnisse im Mittel
wieder verschlechtert. Diese Verschlechterung fällt
größer aus, als die 4% aussagen, da die verwendeten
Ähnlichkeitswerte ja die Summe der ersten Ähnlichkeit und der
ITL-Ähnlichkeit sind.
|

 Abbildung 82: Normierung des Einflusses der Dokumentlänge
Abbildung 82: Normierung des Einflusses der Dokumentlänge