3.5.2.4: Häufigkeit der Terme
In Abschnitt 1.3.6.3
über
Gewichtungsmethoden und beim probabilistischen Retrieval waren
IDF-Maße eingeführt worden, die seltenen Termen höhere
Gewichte zuordnen. Diese Gewichtung wurde vorgenommen, weil seltenen
Termen eine höhere Diskriminationsfähigkeit zugeschrieben wird
(siehe Abbildung 32
). Peat
und Willett (1991) [->]
führen die Misserfolge der automatischen Expansion darauf
zurück, dass dabei vor allem häufige und damit wenig nützliche
Terme gefunden werden. Sie haben diesen Effekt für drei Maße,
das Cosinus-Maß,
das Dice-Maß und das Jaccard-Maß (hier Tanimoto-Maß
genannt), gefunden.
In Abschnitt 1.3.6.5
waren diese
Maße zur Berechnung der Ähnlichkeiten zwischen Dokumenten verwendet worden.
Hier werden damit Ähnlichkeiten zwischen
Termen ti
und
tj
berechnet. Dabei gehen lediglich die Anzahlen
h(i)
und h(j)
der Dokumente ein, in denen die Terme
ti
und
tj
vorkommen, sowie die Anzahl
h(i,j)
der Dokumente, in denen
ti
und
tj
gemeinsam vorkommen. (Die Maße werden hier mit
Dokumenthäufigkeiten formuliert. Setzt man in den Formeln
aus Abschnitt 1.3.6.5
charakteristische Funktionen
(also Vektoren mit den Einträgen 0 und 1) ein, gehen z.B. die Summen der
Quadrate im Nenner des Cosinus-Maßes in solche Häufigkeiten
über.) Für die drei Maße ergeben sich die Formeln:
| cos |
(i,j) |
= |
| h(
i,j) |
 |
| (h(i)
h(j))1/2
|
|
| DICE |
(i,j) |
=sd |
(
i,j) |
= |
| 2·h(i,j)
|
|
| h(i)+h(
j) |
|
und
| TANIMOTO |
(i,j) |
=sJ
|
(i,j) |
= |
| h(
i,j) |
|
| h(i)
+h(j)-h(i,j)
|
|
Betrachtet man die Formeln aus statistischer Sicht, zeigt sich
allerdings, dass sie häufige Terme begünstigen:
Während die angegebenen Maße Ähnlichkeiten
oder Winkel zwischen Vektoren messen, kann man auch überlegen, ob
die Häufigkeit, mit der zwei Terme zusammen auftreten,
zufällig, überzufällig oder unterzufällig
ist.
Falls p(i)
die Wahrscheinlichkeit des Auftretens des Terms
i
in einem Dokument
und p(i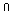 j)
die Wahrscheinlichkeit des gemeinsamen Auftretens der
Terme i
und
j
in einem Dokument bezeichnen, gilt nach
der Definition der statistischen Unabhängigkeit
bei zufälligem gemeinsamen Auftreten der Terme j)
die Wahrscheinlichkeit des gemeinsamen Auftretens der
Terme i
und
j
in einem Dokument bezeichnen, gilt nach
der Definition der statistischen Unabhängigkeit
bei zufälligem gemeinsamen Auftreten der Terme
|
p(ij)=p(i)
·p(j)
|
Der Quotient
| p(ij) |
|
|
p(i)·p(j)
|
|
ist also genau dann
kleiner als
1
, wenn die Terme unterzufällig häufig
zusammen auftreten. Er ist
gleich
1
, wenn sie zufällig häufig zusammen
auftreten, und er ist
größer als
1
, wenn sie überzufällig häufig zusammen
auftreten.
Ersetzt man die Wahrscheinlichkeiten durch relative
Häufigkeiten, erhält man die
Formel
| U |
(i,j) |
=A· |
| h(
i,j) |
|
| h(i)
·h(j) |
|
wobei
A
die Anzahl der Dokumente bezeichnet, die
bei der Berechnung der relativen Häufigkeit herangezogen
wurden, und als konstanter Faktor in den folgenden
Überlegungen ignoriert werden kann.
Vergleicht man diesen Quotienten mit den
Ähnlichkeitsmaßen, so zeigt sich, dass alle drei Maße
häufige Terme stärker begünstigen als dieser.
Der cos(i,j)
z.B. unterscheidet sich von
U(i,j)
durch den Faktor
Fc=(h(i)
h(j))1/2
:
| cos |
(i,j) |
= |
| h(i,j) |
|
| (h(i)h(j))1/2
|
|
| |
= |
| h(i,j) |
|
| h(i)h(j) |
|
|
·(h(i)h(j))1/2
|
|
|
= |
U(i,j)
·(h(i)h(j))1/2
|
Je häufiger ein Term vorkommt, desto größer
ist der Faktor
Fc
. Für die beiden anderen Maße lassen sich ähnliche
Effekte zeigen: Um einen Faktor
FD
für das Dice-Maß zu berechnen setzt
man
mit
f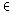 R
.
Dann folgt R
.
Dann folgt
| f= |
| h(i,j) |
|
|
h(i)·h(j)
|
|
· |
| 2(h(i)
+h(j)) |
|
| h(i,j) |
|
=2 |
|
h(i)+h(j)
|
|
| h(i)·h(
j) |
|
und
| f=2( |
| 1 |
|
| h(j)
|
|
+ |
| 1 |
|
| h(i)
|
|
) |
Mit
|
FD= |
| 1 |
|
| f |
|
erhält man schließlich
Auch dieser Faktor
FD
wächst mit zunehmender Häufigkeit der Terme
i
und
j
.
Für das Tanimoto-Maß schließlich führt
zu
| f= |
| h(i,j) |
|
|
h(i)·h(j)
|
|
· |
| h(i)+
h(j)-h(i,j)
|
|
| h(i,j) |
|
und
| f= |
| h(i)+h(
j)-h(i,j)
|
|
| h(i)·h(
j) |
|
= |
| 1 |
|
| h(
j) |
|
+ |
| 1 |
|
| h(
i) |
|
- |
| h(i,j)
|
|
| h(i)·h(
j) |
|
Da
h(i)>=h(i,j)
und
h(j)>=h(i,j)
gilt, folgt
| h(i,j) |
|
| h
(i)·h(j)
|
|
<= |
| h(i)+h
(j) |
|
| h(i
)·h(j)
|
|
<= |
| 1 |
|
| h(j)
|
|
+ |
| 1 |
|
| h(i)
|
|
und damit
| 0<=f<= |
| 1 |
|
| h(j)
|
|
+ |
| 1 |
|
| h(i)
|
|
=:g |
Wobei
f=g
gilt, wenn
h(i,j)=0
ist. Schließlich kann man
|
FT= |
| 1 |
|
| g |
|
setzen und erhält
| sJ |
(i,j) |
= |
|
1 |
|
| f |
|
·U |
(i,j) |
>=FT·U |
(i,j) |
Auch der Faktor
FT
kann also mit zunehmender Häufigkeit der
beteiligten Terme wachsen und damit häufige Terme
begünstigen.
|
