|
In diesem
Abschnitt sollen Methoden vorgestellt werden, mit denen einzelne Terme
in einem Dokument oder einer Anfrage gewichtet, also
Gewichtsvektoren für Dokumente und Anfragen bestimmt werden
können. Die auf den ersten Blick einfachste Methode der
Gewichtung von Termen in Dokumentvektoren besteht darin, die
Terme von Indexierenden gewichten zu
lassen. Das kann bei der manuellen (bzw.
intellektuellen) Indexierung geschehen, insbesondere bei der Vergabe von
Termen aus einem
kontrollierten Vokabular oder bei der Vergabe von
freien Schlüsselwörtern.
Dieses Vorgehen ist aber aus mehreren Gründen problematisch:
Zum einen erfordert es einen hohen Arbeits-, Zeit- und damit
Kostenaufwand. Zum zweiten haben Experimente gezeigt, dass
Versuchspersonen nur schlecht in der Lage sind,
Wahrscheinlichkeiten einzuschätzen und mit ihnen
umzugehen. Schließlich besteht außerdem die Gefahr,
dass die tatsächlich vergebenen Gewichtungen von vielen
Faktoren abhängen, die eigentlich keine Rolle spielen sollten:
zum Beispiel von der Reihenfolge, in der Texte indexiert und bewertet
werden, oder von der Person der Indexierenden und deren
Wissenstand, Interessen und Tagesform. Die Konsistenz der
Gewichtungen dürfte daher noch geringer
sein als bei der ungewichteten Vergabe von
Indextermen.
Auch bei der Konstruktion von Anfragen kann man die Terme von den
Anfragenden gewichten lassen. Aber auch hier ist zu
erwarten, dass Anfragende Probleme haben, mit Gewichtungen konsistent umzugehen.
Zudem stellt die Vergabe von Gewichten eine
zusätzliche kognitive Belastung der Nutzenden
dar.
Die erwähnten Schwierigkeiten legen es nahe, nach automatischen bzw.
halbautomatischen
Methoden zu suchen, mit denen Gewichte berechnet
werden können. Das führt wieder auf die
Frage zurück, wie Terme, die den Inhalt eines
Dokuments gut charakterisieren, automatisch erkannt werden
können.
Beim booleschen Retrieval lässt sich durch eine
Stoppwortliste verhindern, dass sehr häufige Terme in die invertierte Liste aufgenommen werden.
Man geht davon aus, dass sie für die
Repräsentation des Inhalts eines Dokuments nicht wichtig sind
oder zumindest nicht dazu beitragen, wichtige Dokumente von unwichtigen zu unterscheiden.
Dieses Vorgehen kann im Vektorraummodell übernommen werden, indem
als generelle Gewichtung der Terme der Stoppwortliste das
Gewicht 0 verwendet wird, egal in welchem Dokument
oder in welcher Anfrage sie auftreten. Dieses Vorgehen ist allerdings eine ziemlich
grobe Methode, die der Idee des Vektorraummodells nicht gerecht wird. Angemessenere
Methoden werden im Folgenden beschrieben.
Ganz allgemein kann man bei der Bestimmung von
Termgewichten zwischen globalen oder
kontextunabhängigen
Einflussfaktoren
(Between-Object-Einflüsse)
und lokalen oder
kontextabhängigen
Einflussfaktoren
(Within-Object-Einflüsse)
unterscheiden. Ein lokales oder kontextabhängiges Kriterium
für die Wahl bzw. Gewichtung von Termen wäre z.B. die
Häufigkeit, mit der ein Term in einem Dokument
auftritt.
Häufig werden lokale und globalen Gewichtungen zu Formeln vom
Typ
| wi,j= |
| h(i,j) |
 |
| d
(j) |
|
verknüpft, indem die Termhäufigkeit (TF)
mit der invertierten Dokumenthäufigkeit (IDF) multipliziert wird.
Gewichtsformeln von diesem Typ werden auch als
TF-IDF-Gewichtung
bezeichnet
(term frequency-inverted document
frequency). Sie sind in vielen Systemen und
Untersuchungen erfolgreich eingesetzt worden.
Eine komplexere Formel, die für das experimentelle System SMART
(Salton und McGill, 1983 [->]
)
entwickelt wurde, lautet z.B.:
| wi,j~=
|
| 1 |
|
| 2 |
|
| (1+ |
| h(i,j) |
|
|
|
| max |
k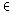 {
1,...,n} {
1,...,n} |
|
{h(i,k)} |
|
| ) |
ln( |
| m |
|
| d(j)
|
|
| )
|
bzw. als normierte Version:
| wi,j= |
| w~i,j
|
|
| ( |
| n |
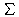 |
| k=1 |
|
w~i,k2)1/2 |
|
|

 1.3.6.3.1: Globale Gewichtungseinflüsse
1.3.6.3.1: Globale Gewichtungseinflüsse