1.3.6.3.1: Globale Gewichtungseinflüsse
Bei den globalen oder kontextunabhängigen Gewichtungsfaktoren ist das weitaus am häufigsten
verwendete Kriterium die Häufigkeit eines Terms in der Sprache bzw. in einer
Dokumentensammlung. Die Verteilung der Wörter in der Sprache kann grob
durch das zipfsche Gesetz beschrieben werden.
Es besagt, dass das Produkt der Häufigkeit eines Worts
mit seinem Häufigkeitsrang in etwa konstant ist (siehe
Abbildungen 30
und 31
):
Aus dem zipfschen Gesetz ergibt sich auch, dass die
Häufigkeit der Terme in etwa mit
| h |
(w) |
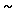 |
| c |
 |
|
r(w) |
|
abnimmt. Daraus folgt, dass eine kleine Anzahl von häufigen
Wörtern einen großen Anteil der Texte abdeckt und
die große Anzahl der seltenen Wörter
nur einen kleinen Anteil des Textes ausmacht.
Nimmt man nun (unrealistischerweise) an, dass jedes
einzelne Wort im Korpus in etwa gleich verteilt ist, zeigt sich, dass
wegen der starken Häufigkeitsunterschiede
die häufigen Wörter in fast jedem Textteil erwartet werden
können. Andererseits treten seltene
Wörter nur in sehr wenigen Texten auf. Häufige Terme sind also
keine guten Suchterme, weil sie nicht spezifisch für
einen Text sind. Bei seltenen Termen kann man nicht erwarten, dass
sie in allen relevanten Texten vorkommen.
Übrig bleiben bei der Suche nach geeigneten Suchtermen die Terme mittlerer Häufigkeit, die zwar
häufig genug sind, um genügend relevante Inhalte abzudecken, aber
auch signifikant genug, um nicht relevante Texte
auszuschließen (siehe Abbildung 32
).
In der Praxis werden seltene Terme oft nicht gesondert behandelt, es
wird also nur der erste Teil der Überlegung angewendet.
Anstelle der Häufigkeit von Termen wird im
Information Retrieval oft die
Dokumenthäufigkeit
(document frequency)
verwendet: Das ist die Anzahl der
Dokumente, in denen ein Term auftritt. Geht man wieder von einer zufälligen
Verteilung eines Worts in einem Korpus von Dokumenten aus, so werden
durch den Übergang von der Häufigkeit zur
Dokumenthäufigkeit die Häufigkeitsunterschiede besonders für häufige Terme
verringert: Bei der Bestimmung der Dokumenthäufigkeit
spielt es keine Rolle, ob ein Term oft in einem Dokument vorkommt oder
nur einmal.
Während eine Stoppwortliste beim
booleschen Retrieval eine harte Häufigkeitsschranke für den
Ausschluss setzt, lässt sich der Einfluss der Häufigkeit
mit der Möglichkeit, Terme zu gewichten, differenzierter
modellieren. Meistens wird dazu eine Form der so genannten
inversen (oder auch
invertierten)
Dokumenthäufigkeit
(inverted document frequency,
IDF)
verwendet:
| wi,j=idf |
(j) |
= |
| 1 |
|
|
d(j) |
|
Dabei bezeichne
D=(d1,...,dm)
wieder die Menge der
Dokumente,
T=(t1,...,tn)
die der Terme und
d(j)
die Anzahl der Dokumente, in denen Term
tj
vorkommt. In der Praxis werden auch modifizierte Formen verwendet,
wie
| wi,j=ln |
( |
| m |
|
| d(
j) |
|
)
|
oder
| wi,j=ln |
( |
| m-d(j)
|
|
| d(j) |
|
)
|
wobei
ln
den natürlichen Logarithmus bezeichnet.
Diesen Formeln ist gemeinsam, dass ihr Wert mit wachsendem
d(j)
monoton fällt. Der Logarithmus dämpft große Werte,
schwächt also in diesen Formeln die Gewichte seltener Terme wieder etwas ab.
Andere globale Einflussfaktoren werden in der Praxis
kaum genutzt. Ein mögliches Kriterium wäre z.B. die
Verteilung eines Terms auf die Dokumente: Terme, die über die
Dokumente gleichmäßig verteilt sind, sollten weniger spezifisch sein als
solche, die in einzelnen Dokumenten mit hoher Häufigkeit auftreten,
in anderen dagegen gar nicht.
Da die globalen Gewichtungsfaktoren nicht vom konkreten Auftreten
der Terme bzw. Attribute in den einzelnen Dokumenten abhängen,
lassen sie sich bei der Implementierung mit
invertierten Listen im
Prinzip separat speichern bzw. aus den Positionslisten der
invertierten Liste jeweils aktuell berechnen. Wie weit sich der
zusätzliche Aufwand dafür lohnt, muss im Einzelfall entschieden werden.
|

 Satz 1: Zipfsches Gesetz
Satz 1: Zipfsches Gesetz