1.3.6.3.2: Lokale Gewichtungseinflüsse
Auch bei den kontextabhängigen Einflussfaktoren wird vor allem die
Häufigkeit eines Terms in einem Dokument zur Berechnung von Termgewichten herangezogen
(Termhäufigkeit,
term frequency,
TF).
Dabei wird im Allgemeinen davon ausgegangen, dass Terme, die häufig in einem Dokument auftreten,
für die inhaltliche Beschreibung wichtiger sind als solche, die nur selten auftreten.
Im einfachsten Fall kann die Häufigkeit
eines Terms in einem Dokument direkt in der Form
verwendet werden. Dabei bezeichnet
h(i,j)
die Häufigkeit von
Term
tj
im Dokument
di
. Andere Formeln beschränken die Gewichte auf ein Intervall
und dämpfen den Einfluss sehr häufiger
Terme, wie z.B. die Formel
| wi,j= |
| h(i,j) |
 |
| 1
+h(i,j) |
|
In längeren Texten
werden die Häufigkeiten von Termen im Allgemeinen größer
sein als in kurzen. Um diesen Effekt auszugleichen, kann man die
Häufigkeit eines Terms zu der des häufigsten Terms im Text in
Relation setzen:
| wi,j=K+(1-K) |
| h(
i,j) |
|
|
| max |
l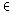 {1,...n} {1,...n} |
| h(i,l) |
|
K[0,1]
bezeichnet dabei einen
Parameter, mit dem bestimmt werden kann, wie groß
der Einfluss der Gewichtung sein soll. Wird
K=0
gesetzt, wird nur die Häufigkeitsgewichtung
verwendet, für
K=1
spielt sie keine Rolle und es wird für alle
Terme das konstante Gewicht
1
vergeben. (Die Formel wird dann sinnvoller Weise nur
für Terme verwendet, die in einem Dokument auftreten. Terme, die
nicht auftreten, erhalten das Gewicht
0
.)
Andere lokale Gewichtungsmethoden nutzen Informationen
über die Struktur der verwalteten
Dokumente. Dokumente in Literaturdatenbanken, wie
sie z.B. in Abbildung 1
dargestellt wurden, haben
verschiedene Felder, denen unterschiedliche Gewichtungen zugeordnet werden können. So kann ein
Term, der in einem Titel auftaucht, höher gewichtet werden als
einer, der im Abstract eines Dokuments auftaucht.
Ähnliche Möglichkeiten bieten Dokumente, die
eine logische Struktur aufweisen wie Texte, die
mit SGML (Standard Generalized Markup Language) (siehe Abschnitt 4.1.1
)
oder Latex formatiert sind.
Bei solchen Dokumenten sind verschiedene Textteile wie Kapitel, Sektionen, Absätze oder
die dazugehörigen Überschriften im Quelltext markiert. Dadurch
können z.B. Terme, die in einer Kapitelüberschrift
auftauchen, stärker gewichtet werden als solche, die nur in einer
Fußnote auftauchen.
Auch die Position eines Terms in einem Text kann zur Gewichtung genutzt werden.
Meldungen von Nachrichtenagenturen weisen z.B. häufig eine ziemlich
verlässliche inhaltliche Struktur auf: Zunächst wird die
wesentliche Neuigkeit mitgeteilt, die der Grund
der Meldung ist, dann werden die Hintergründe kurz
erläutert und schließlich werden noch
Details und Kommentare angeschlossen. Hier ist
es also sinnvoll, Terme, die am Anfang des Textes stehen,
höher zu gewichten als später
auftretende Terme. Auch einige Web-Suchmaschinen scheinen die Position von
Termen in diesem Sinne zu gewichten.
|
