4.3.4.3: Ranking nach externen Daten
Neben Eigenschaften, die sich direkt aus den Web-Angeboten selbst ablesen lassen,
können auch weitere Daten über die Dokumente benutzt werden, um eine gute Rangordnung
der Dokumente zu bestimmen.
Besonders interessant sind dabei natürlich Angaben, die von (möglichst fachkundigen) Menschen
gemacht werden, also manuelle Indexierungen, Beschreibungen und Beurteilungen oder Verweise
auf eine Seite.
Manuell erstellte Web-Verzeichnisse (siehe Abschnitt 4.3.3
) sind eine beliebte
Quelle für solche Daten. In ihnen liegen Klassifikationen und Beurteilungen einzelner Seiten und
Angebote vor, die für die Suche gemacht wurden und daher besonders geeignet sein sollten,
die Suchergebnisse zu verbessern. Die Klasse, in die eine Seite eingeordnet wurde,
kann z.B. als
hoch gewichteter Eintrag in den Dokumentvektor aufgenommen werden. Eine Beschreibung der Seite kann
ebenfalls als hoch gewichteter Textteil verwendet werden. Liegt eine explizite Bewertung vor,
kann diese als globaler Faktor auf den Dokumentvektor verwendet werden.
Während mit Web-Verzeichnissen Informationen genutzt werden, die als Beschreibungen und
Bewertungen für die Suche gemacht wurden, gehen andere Verfahren einen Schritt weiter und
verwenden mit der Verweisstruktur, also den Links im Web, Daten, die zwar als Verweise
zwischen Informationseinheiten angelegt, aber nicht ausdrücklich für die Suche
gemacht wurden.
Dieser Ansatz kann als eine Art Social Filtering angesehen werden, bei dem
die Verweise allerdings nicht explizit bewertet sind. Trotzdem scheint die Verwendung der
Information aus der Verweisstruktur ein recht guter Ansatz zu sein, wenn sie entsprechend
eingesetzt wird.
Er wird z.B. im so genannten PageRank-Algorithmus der Suchmaschine Google verwendet
(Brin und Page, 1998 [->]
).
Dieser Algorithmus, dessen Name übrigens als Warenzeichen registriert ist, soll im Folgenden genauer
beschrieben werden, soweit das mit den Angaben aus dem genannten Artikel möglich ist.
Dokument-Dokument-Matrizen
Die Verweisstruktur des Web kann dazu verwendet werden, eine Rangordnung aller Dokumente
zu berechnen. Nach dieser einmal berechneten Rangordnung können dann die Dokumente einer
gefundenen Ergebnismenge geordnet werden.
Das Verfahren zur Berechnung der Rangordnung geht davon aus, dass
Dokumente, auf die viele Verweise zeigen, gut sind. Das ist ein ähnliches Modell, wie es
bei Zitierindices angewendet wird. Auch dabei werden Dokumente (bzw. ihre Autorinnen oder Autoren)
hoch bewertet, wenn sie oft von anderen Dokumenten (bzw. Autorinnen und Autoren) zitiert werden.
Über ihre reine Anzahl hinaus
werden bei PageRank die Verweise auch noch danach gewichtet, wie viele Verweise von der
Ursprungsseite insgesamt ausgehen.
Formal wird das von Brin und Page (1998) als Lösung eines
linearen Gleichungssystems formuliert:
Man kann die Formel (214
) auch anders darstellen,
indem man eine Verbindungsmatrix der Dokumentensammlung konstruiert, also eine quadratische Matrix
W = {wi,j} , deren Seitenlänge der Anzahl der Seiten
d1, ... , dm
entspricht. Ein Eintrag
wi,j
ist gerade dann gleich
1, wenn ein Verweis vom Dokument
dj
auf das Dokument
di
existiert, sonst ist er
0. Die Anzahl der Verweise in einem Dokument ergibt sich dann als
| out(j)= |
| n |
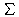 |
i=1, i  j j |
|
wi,j |
.
Die Gleichung (214
) geht damit in die Gleichungen
|
r(i)=(1-d) + d |
| n |
|
| j=1, j i |
|
| wi,j r(j) |
 |
| out(j) |
|
und
|
0 = ( 1 - d ) - r ( i ) + d |
| n |
|
| j=1, j i |
|
| wi,j r(j) |
|
| out(j) |
|
über, die wiederum mit
| wi,i = |
| -out(i) |
|
| d |
|
als
|
d - 1 = d |
| n |
|
| j=1 |
|
| wi,j r(j) |
|
| out(j) |
|
geschrieben werden kann.
Das Ganze lässt sich für
i = 1, ... , n
zur Gleichung
zusammenfassen, wobei jetzt
(d-1)
und
r
Vektoren mit
n
Einträgen sind, während
d
ein Skalar (also eine reelle Zahl) ist.
Eine Lösung dieser Gleichung kann durch ein Iterationsverfahren berechnet werden:
Man beginnt mit einem beliebigen Vektor und multipliziert ihn immer wieder mit
der Matrix (siehe z.B. Überhuber, 2002 [->]
).
Dieses Verfahren ist häufig sogar
der beste Ansatz, um eine Lösung des Gleichungssystems zu berechnen, da die Matrix
W
in der Regel eine schwach besetzte Matrix ist, also die Mehrzahl der Einträge gleich
0
ist. Bei diesem Verfahren konvergiert der berechnete Vektor gegen den Eigenvektor zum
größten Eigenwert der Matrix
W.
Dieser Eigenvektor gibt sozusagen die zentrale Richtung der Verbindungsmatrix an.
Wie schon in den Abschnitten 3.4.3
und 3.5.2.7
beschrieben,
kann man die Gleichung (218
) auch als eine
Spreading-Activation-Gleichung in einem Netz lesen: Mit ihr wird für einen Knoten
i
im Netz der verlinkten Dokumente eine neue "Aktivität" aus den "Aktivitäten" der
anderen Knoten berechnet. Im Unterschied zu den oben genannten Systemen sind die Knoten
dieses Spreading-Activation-Netzes Dokumente und keine Terme. Der Aktivität eines Knotens
entspricht der berechnete Rang des Dokuments.
Analog zu der Bezeichnung Term-Term-Matrix aus Abschnitt 3.5.2.2
kann
die Verbindungsmatrix auch als Dokument-Dokument-Matrix bezeichnet werden. Im Unterschied zur
Term-Term-Matrix aus Abschnitt 3.5.2.2
, deren Einträge aus der Kookurrenz
von Termen in Dokumenten berechnet wurden, wird die Dokument-Dokument-Matrix für den
PageRank-Algorithmus aus den Verweisen abgelesen. Zusätzliche
Gewichte werden zunächst nur dadurch eingebracht, dass die Gewichte durch die Anzahl der
Verweise, die in einem Dokument vorkommen, geteilt werden. Weitere Gewichtungen sind aber
natürlich möglich. So erwähnen Brin und Page 1998 z.B., dass die Wichtigkeit der
Ursprungsseiten mit in die Gewichte eingehen kann.
Es zeigt sich also, dass die Grundidee der äußerst erfolgreichen Suchmaschine "Google"
auf der Assoziationstheorie beruht, die bereits bei den assoziativen Regeln
(Abschnitt 1.1.10
) und
in den Kookurrenzmodellen (Abschnitt 3.5.2
) verwendet wurde.
Sie bildet im Wesentlichen die zentrale Tendenz eines Korpus ab und ist deshalb
sehr geeignet, gängige (menschliche) Assoziationen aus einem Korpus zu
extrahieren. In Kombination mit anderen leistungsfähigen Suchmechanismen
kann sie daher gut die "im Allgemeinen" wichtigsten Dokumente zu einer Anfrage
bestimmen.
Verwendung von Ankertexten
Außer als eine Art "Abstimmung" über die Qualität von Dokumenten
können Verweise auch noch in anderer Weise genutzt werden: Da sie in
HTML von einer bestimmten textuellen Position ausgehen, kann man Terme aus
dem "Ankertext" (also dem Text, der in dem Ankerelement oder
A-Tag, das den Ausgangspunkt des Verweises definiert, eingeschlossen wird) oder aus der
Umgebung des Ankers als eine Beschreibung des Inhalts des Zieldokuments auffassen und sie als
weitere Indexterme des Zieldokuments in den Dokumentvektor einfügen. Auf diese
Weise können nicht nur Textdokumente, sondern auch Bilder oder andere Datenformate
indexiert werden.
Dabei kann es natürlich vorkommen, dass Indexterme zu einer
Dokumentbeschreibung hinzugefügt werden, die zumindest nicht im Sinne des
Anbieters dieser Seite sind. So gab es den Fall, dass in einer Web-Seite mit einem beleidigenden
Ankertext ("dumb motherfucker") auf ein Web-Angebot mit Werbeartikeln eines amerikanischen
Präsidentschaftskandidaten verwiesen wurde. In der Suchmaschine Google, die Ankertexte verwendet,
wurde dieses Angebot als Treffer angezeigt, wenn der beleidigende Text eingegeben wurde.
Da das Angebot, auf das verwiesen wurde, im PageRank-Algorithmus wohl eine hohe Wertung bekommen hatte
(die ja aus der Anzahl der Verweise auf das Angebot berechnet wird, nicht aber aus dem Ankertext),
wurde es als erster Treffer in der Trefferliste angegeben. Dieses Ergebnis wurde von Google zwar als
"Programmfehler" bezeichnet, lässt sich mit den verwendeten Algorithmen aber gut erklären.
Es stellt sich allenfalls die Frage, warum ein einziger Verweis bereits zu einer Indexierung
mit dem Ankertext geführt hat. Aber auch das ist nicht unbedingt erstaunlich, wenn man bedenkt,
dass es vermutlich viele einmalige Ankertexte gibt (wenn man von Ankertexten wie "hier" bzw. "here"
absieht). Die Tatsache, dass das Angebot mit dem inkriminierten Suchbegriff gefunden wurde,
sagt ja auch nichts darüber aus, ob und wie häufig es mit anderen Suchanfragen gefunden werden kann
oder konnte.
|

 Definition 25: PageRank
Definition 25: PageRank